整个文章都是参考学习:
Java文件上传大杀器-绕waf(针对commons-fileupload组件)
Tomcat 用的都是 9.0.65 的版本
commons-fileupload 的一些绕过
首先用 gpt 写一个文件上传:
然后很巧的是他用的就是 commons.fileupload,生成的代码如下:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
这里用的是 github 下载下来的源码,自己编译的 jar 包放进 lib 里,这样源码对的上。
https://github.com/apache/commons-fileupload
下的1.5的版本。
关键点应该:

然后一路到这里:
1 | org.apache.commons.fileupload.FileUploadBase.FileItemIteratorImpl#FileItemIteratorImpl |
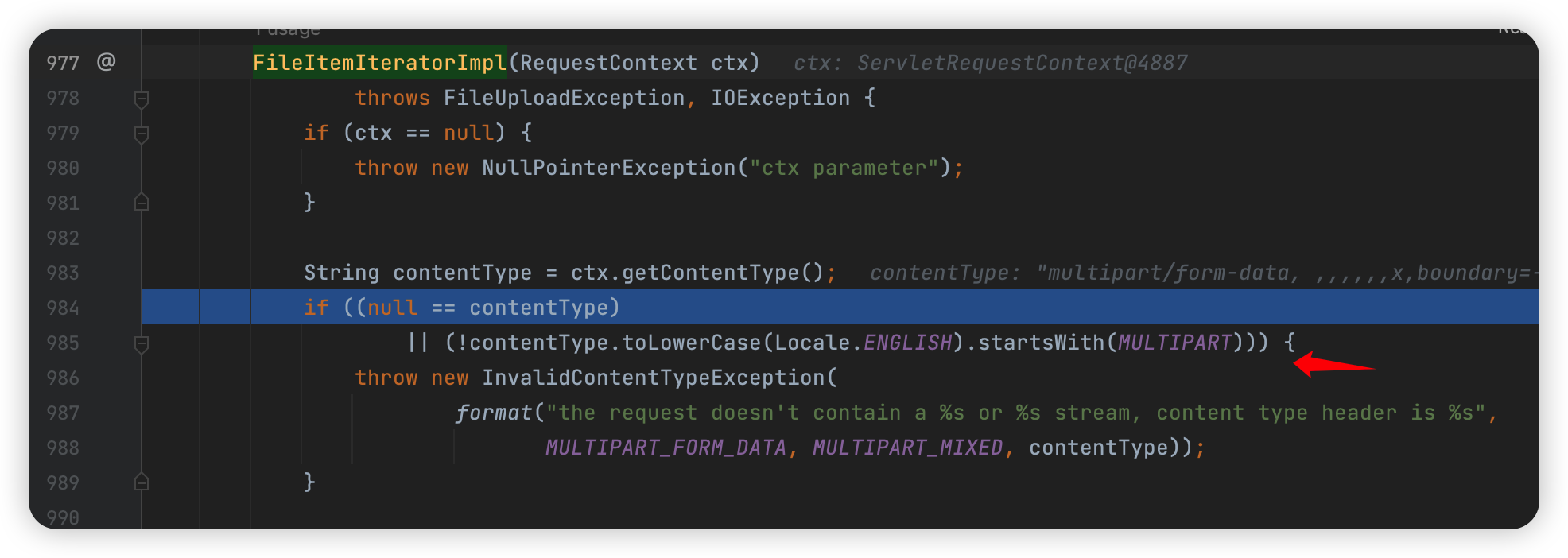
首先判断是不是以 multipart/ 开头,这里执行了 toLowerCase,我还以为可以用 unicode 的那个姿势,试了一下好像不行~

然后就是获取 boundary:
1 | org.apache.commons.fileupload.FileUploadBase#getBoundary |
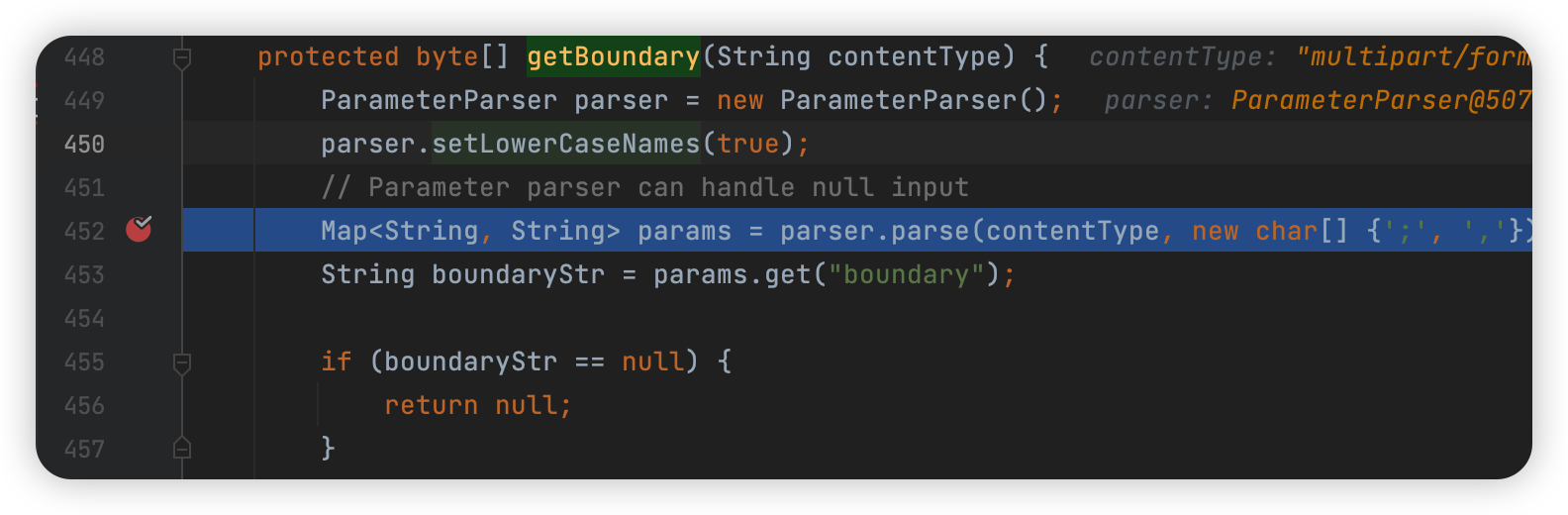
这是第一处 parse,传入的是 header 里的 ContentType,分隔符是 ; 和 ,
然后跟到 parse:
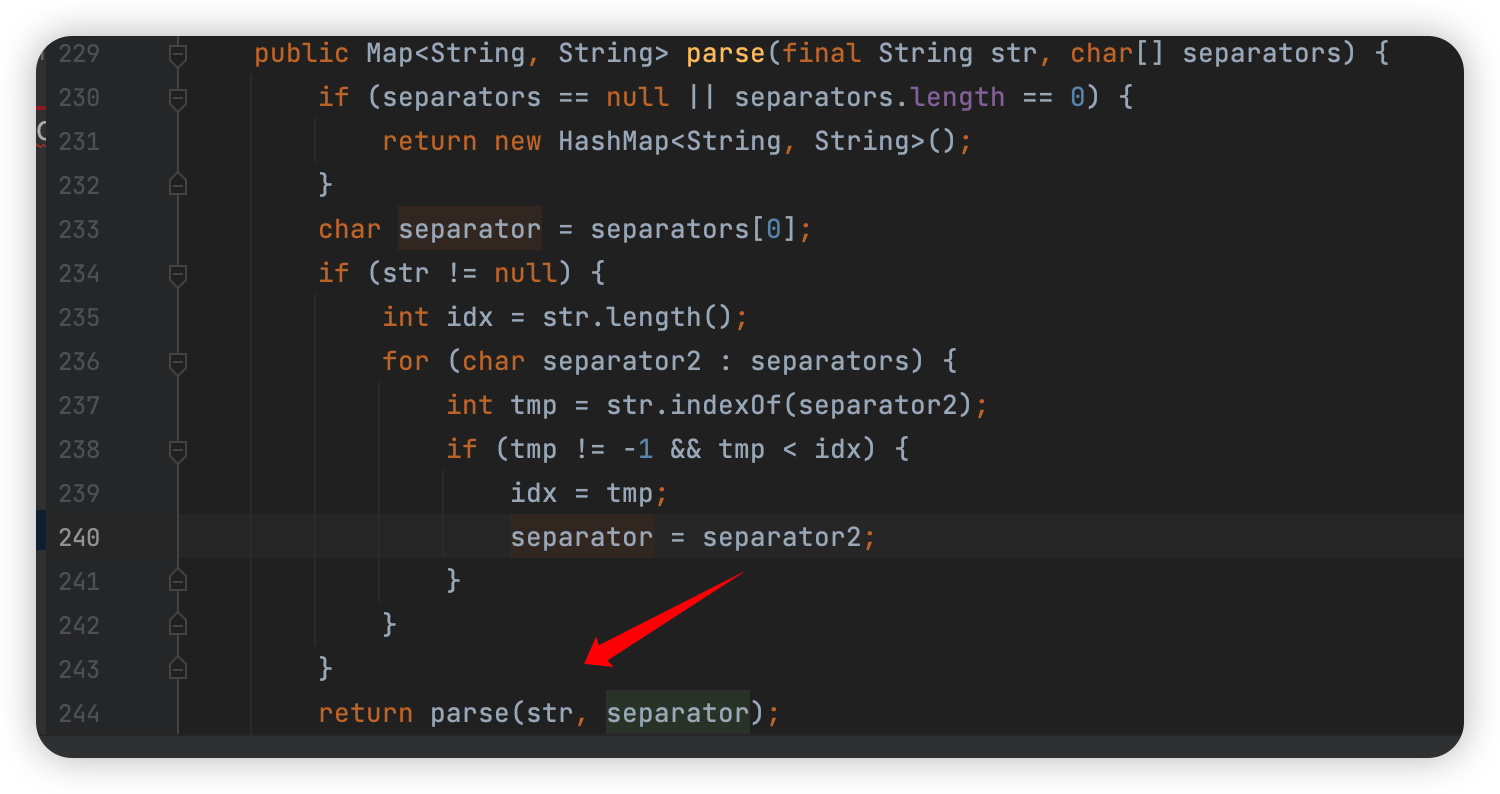
这里应该就是匹配分隔符是什么,匹配到了分隔符就确定是这个分隔符,也就是说 Content-Type 这里是可以以 , 作为分隔符的,例如(当然不能同时用,和;):
1 | Content-Type: multipart/form-data,,,,,,, boundary=----WebKitFormBoundaryAcmP3NxZ67jpA2BL |
然后进入到:
1 | org.apache.commons.fileupload.ParameterParser#parse(char[], int, int, char) |
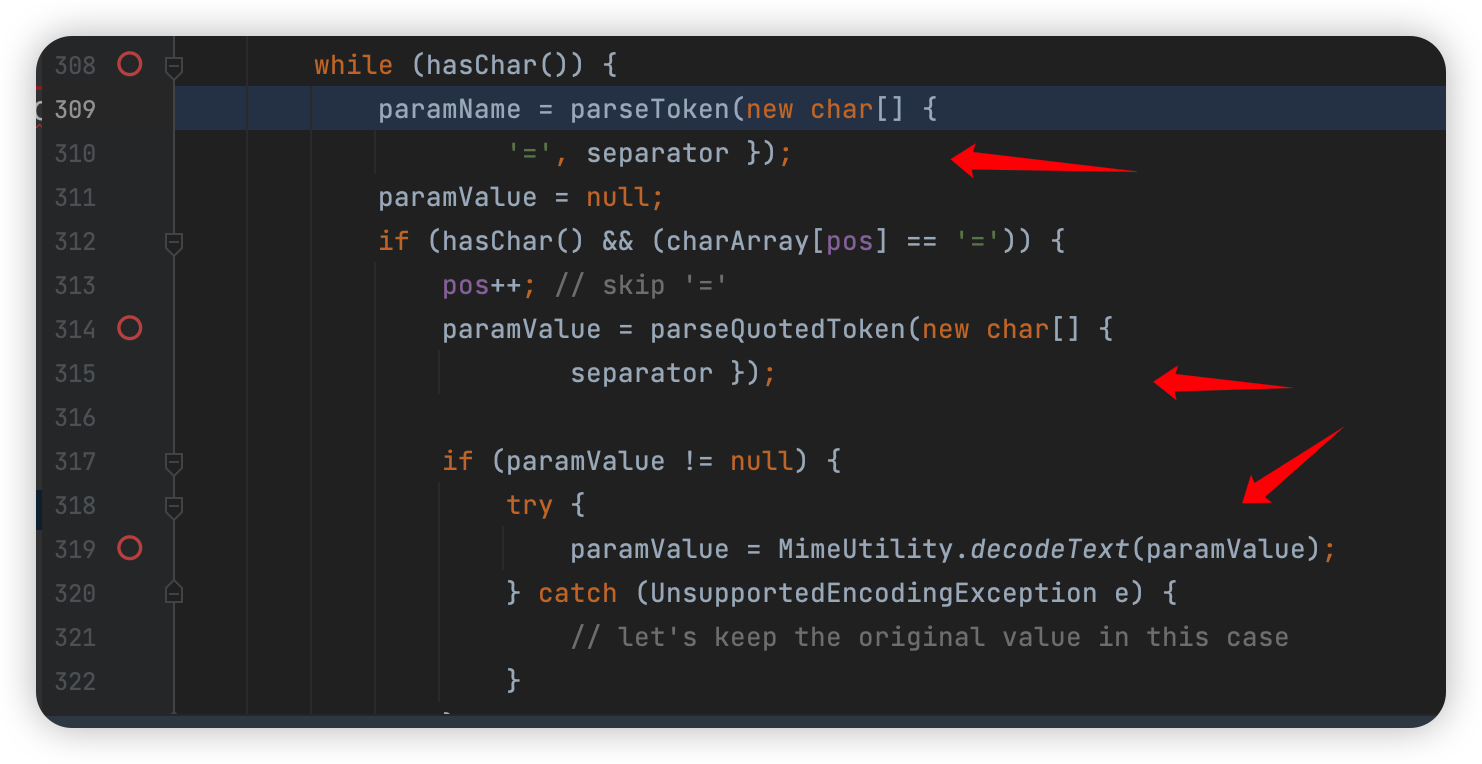
首先上面是去找 = 或者 分隔符,然后如果没有等于号而是直接一个分隔符的话,就直接转小写然后放进数组里:
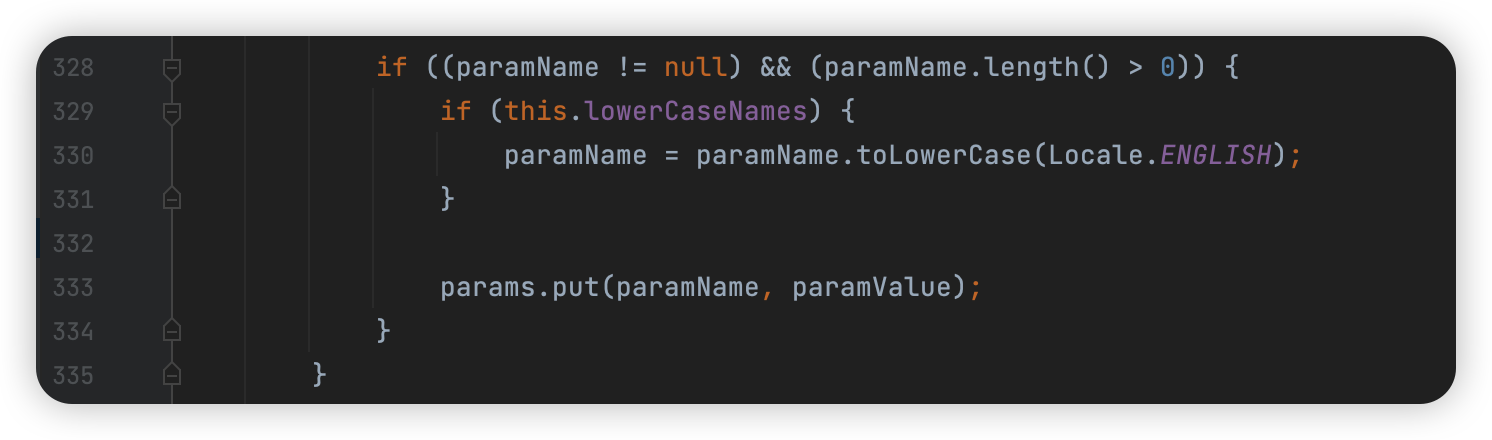
类似上面的那个 multipart/form-data。
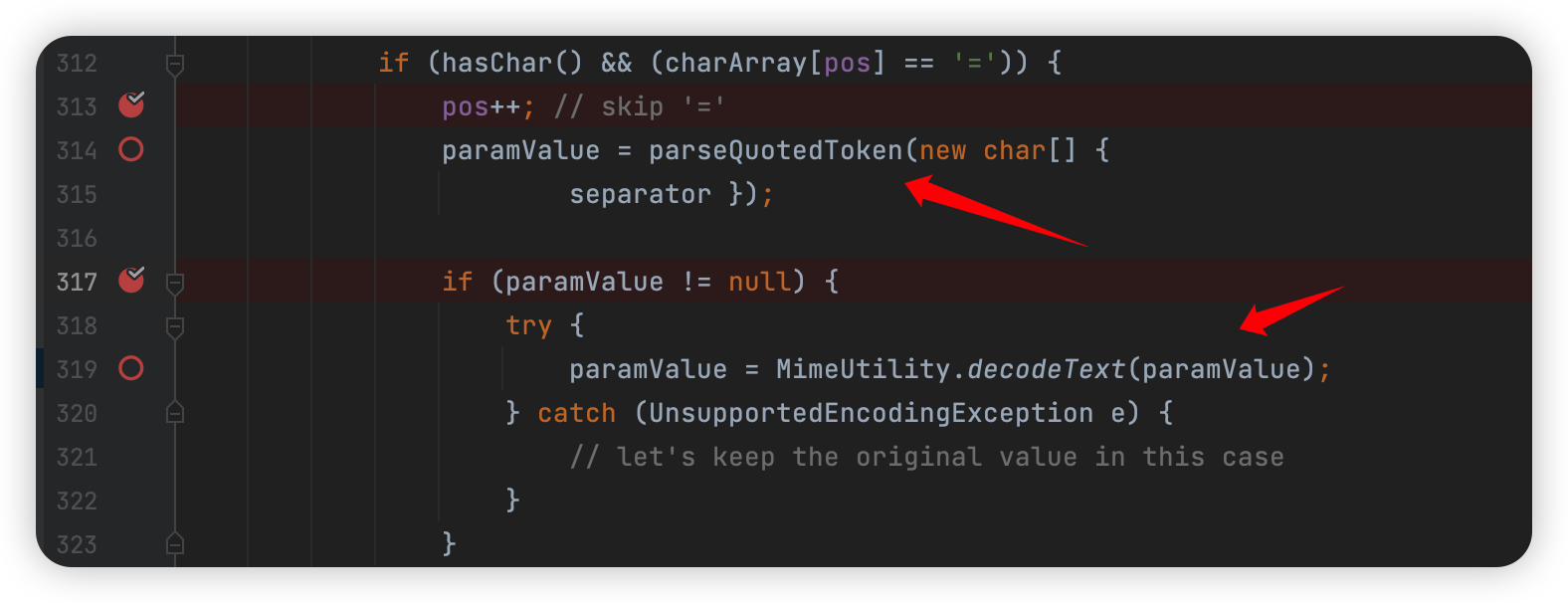
这里首先进入 parseQuotedToken ,匹配的也是 separator 分隔符,大概看一下:
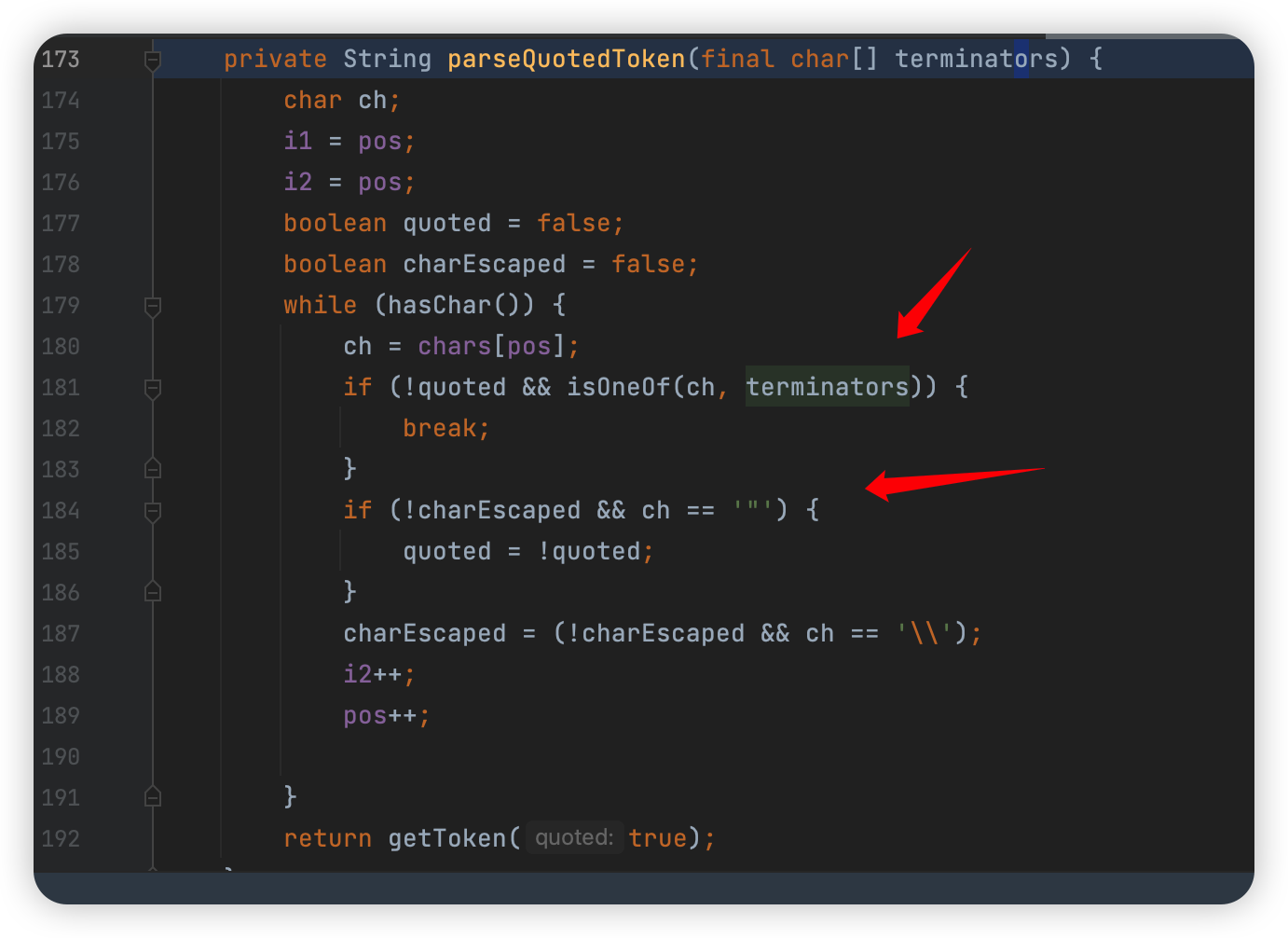
匹配到分隔符并且不在双引号内,就直接跳出,或者要么没有双引号的话,就会直接一直到最后的字符。
所以可以构造一个这样的:
1 | Content-Type: multipart/form-data,,,,,,, boundary="----WebKitFormBoundaryAcmP3NxZ67jpA2BL",123456" |
然后最关键的点来了,从 parseQuotedToken 出来以后,会把 value 传进 decodeText:
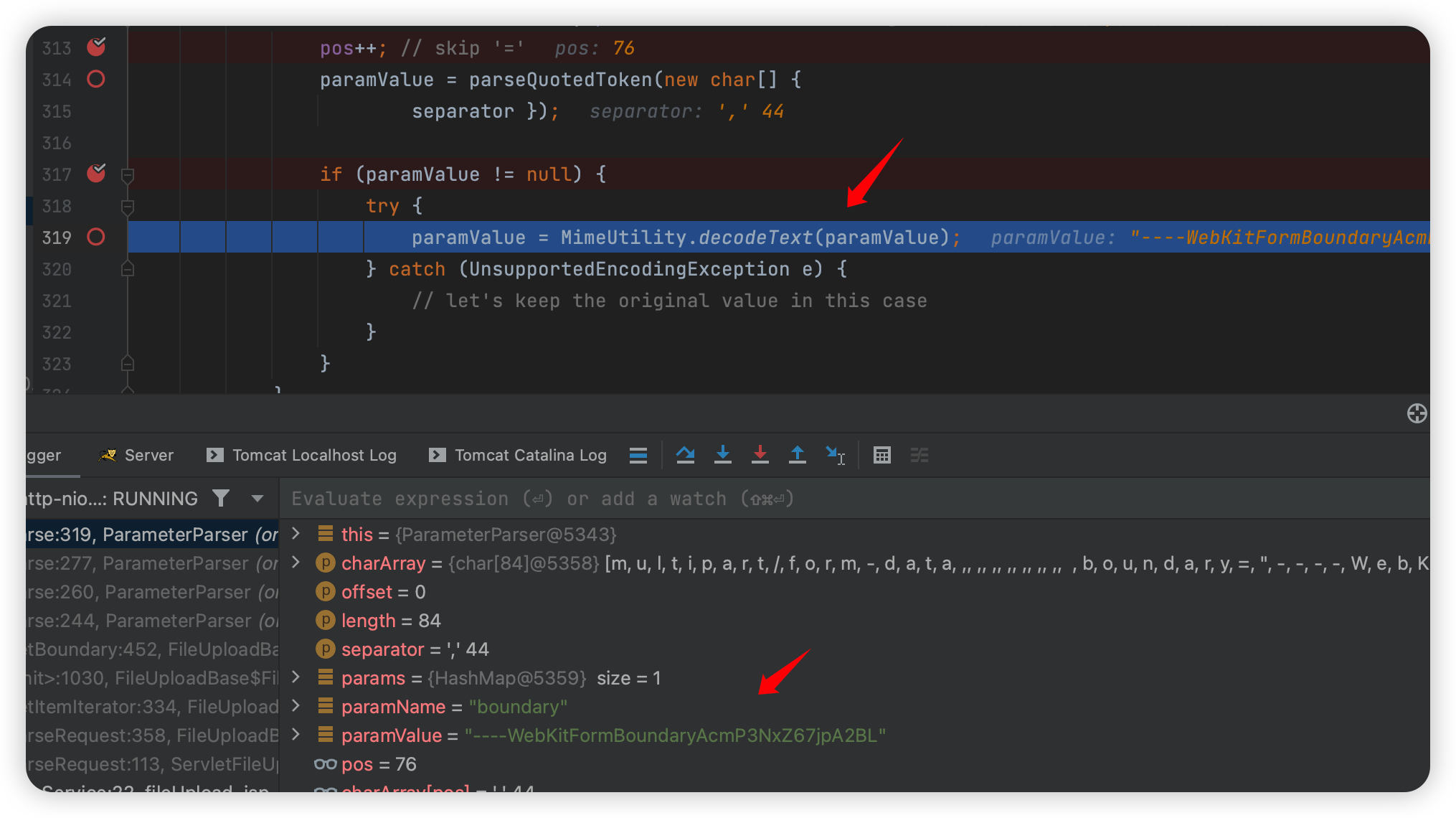
org.apache.commons.fileupload.util.mime.MimeUtility#decodeText
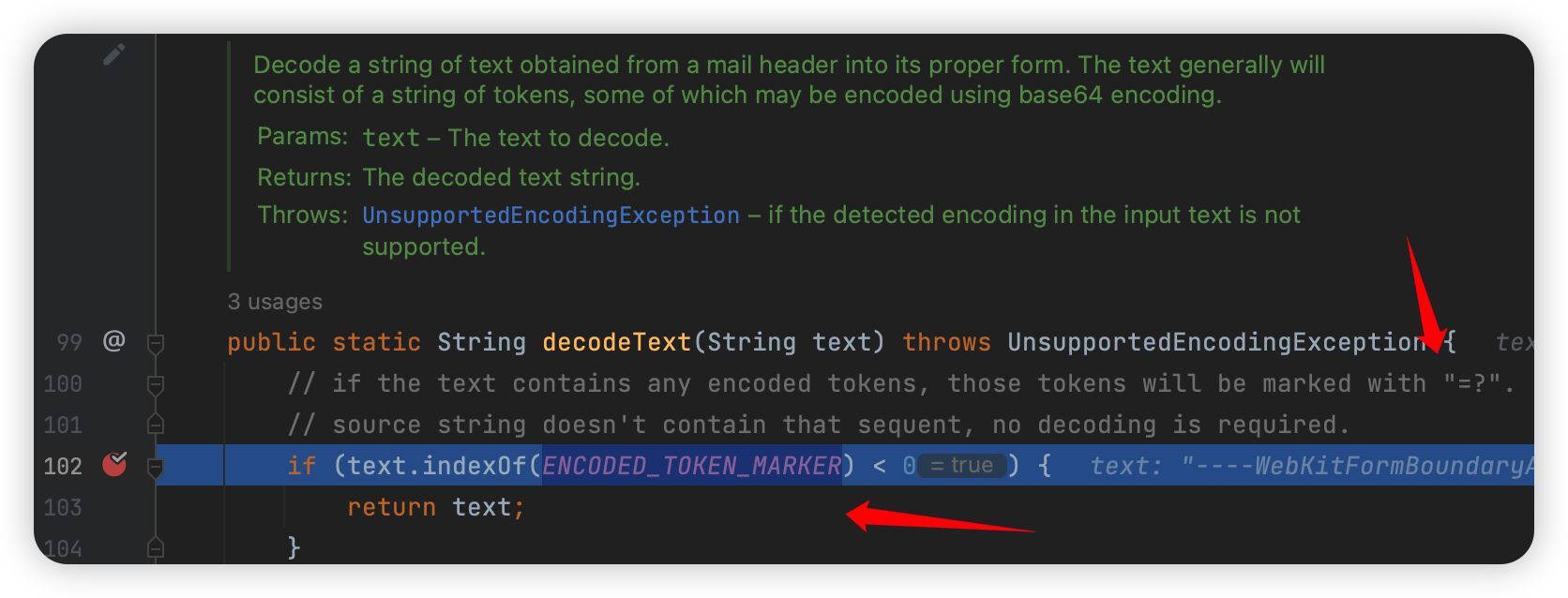
首先判断是不是有 =? ,如果有才会往下进行,我们看看下面发生了什么:
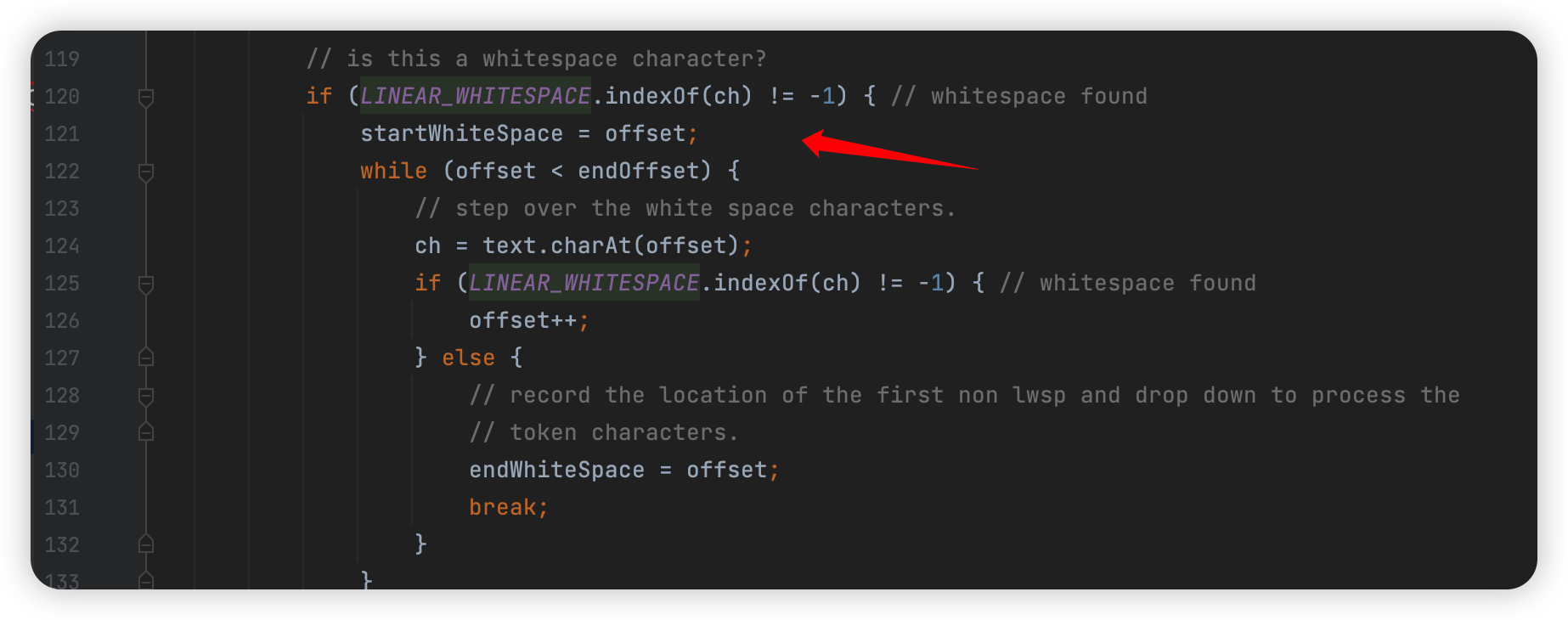
首先判断如果有 \t\r\n 在开头那就统统跳过,然后往下:
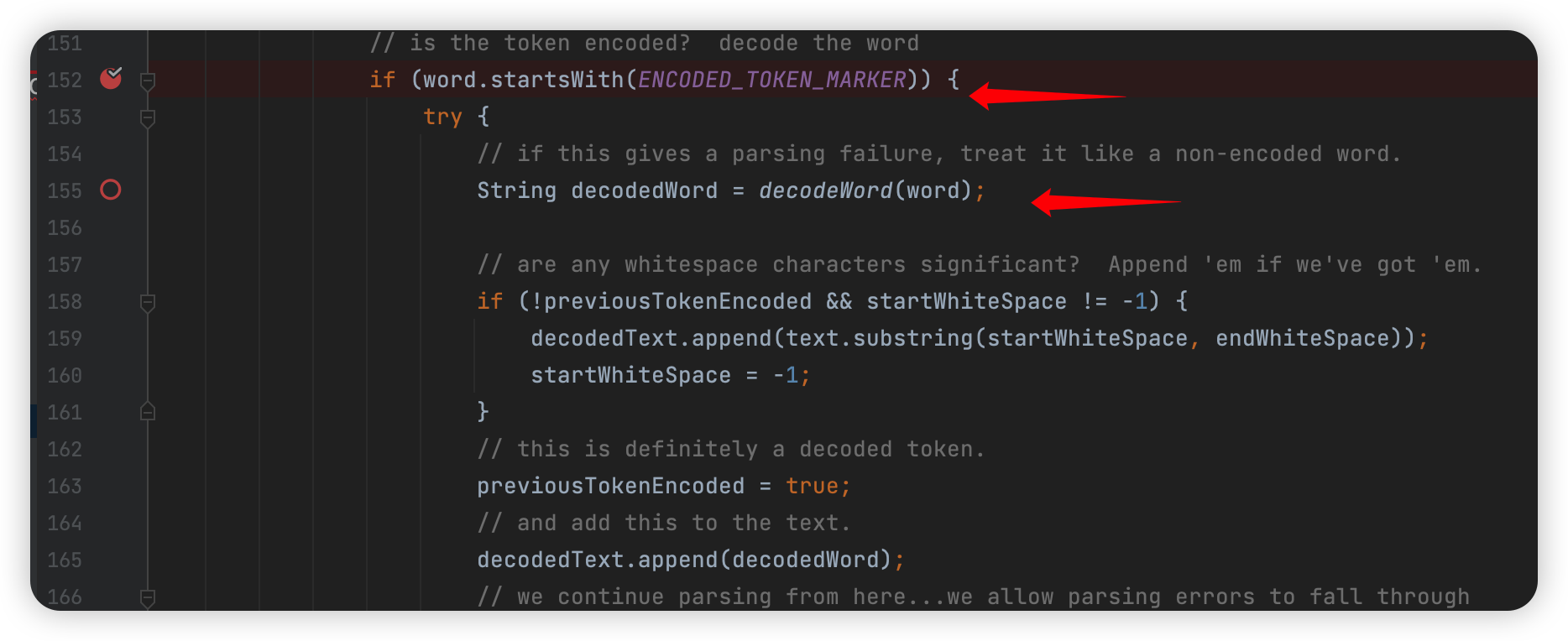
判断是否是 =? 开头的,如果是就会传入 dcodeWord 函数:
1 | org.apache.commons.fileupload.util.mime.MimeUtility#decodeWord |
首先再次判读是否以 ?= 开头,然后获取第二个问号之前的字符当作 charset:
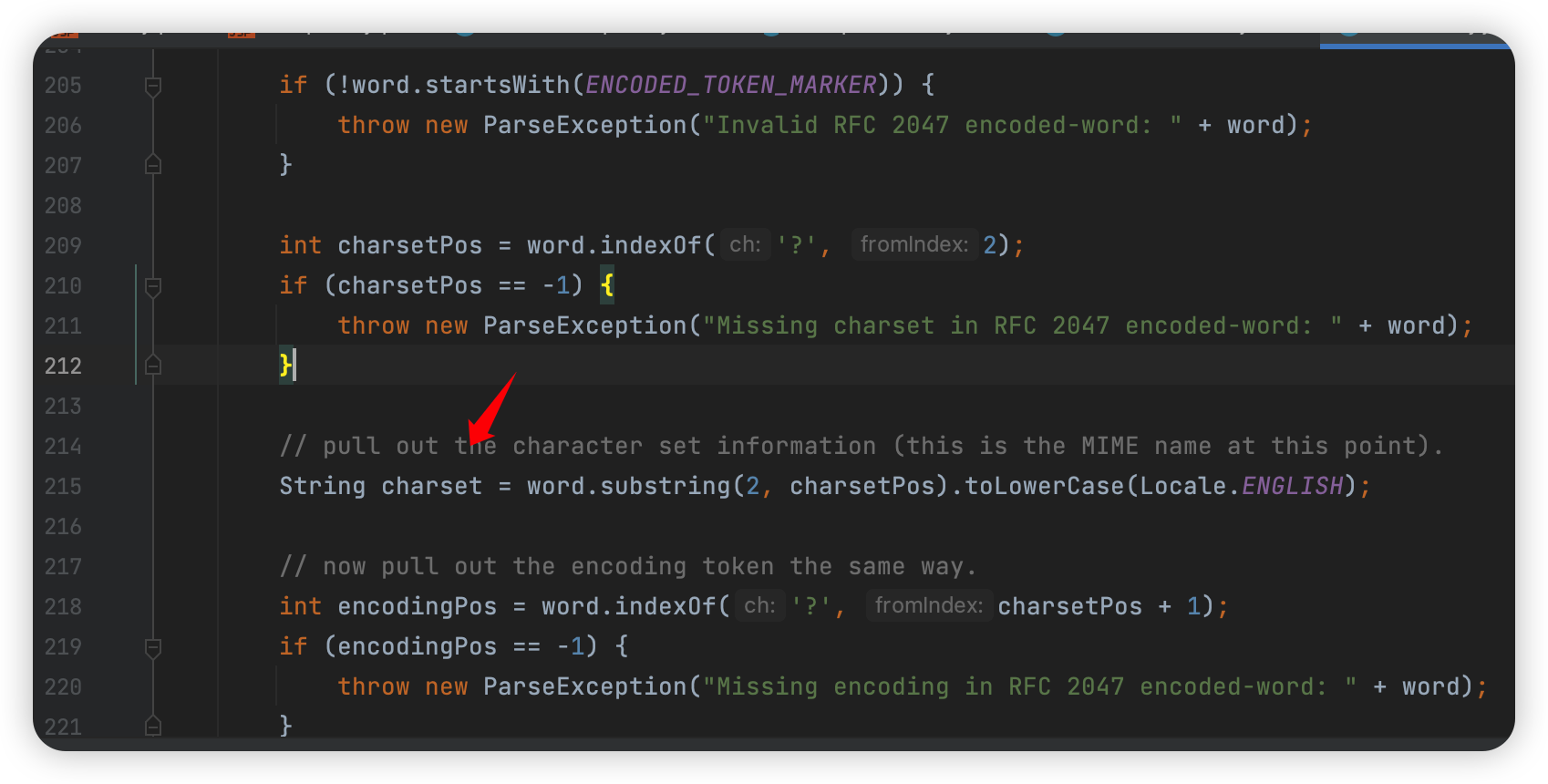
然后还要获取 encoding 以及判断是否有 ?= 作为字符串的结尾:

最后就是 encodedText了,大概结构长这样:
1 | =?charset?encoding?encodedText? |
这里还提到了 RFC 2047 ,那么就可以参考:
https://www.rfc-editor.org/rfc/rfc2047
然后往下:
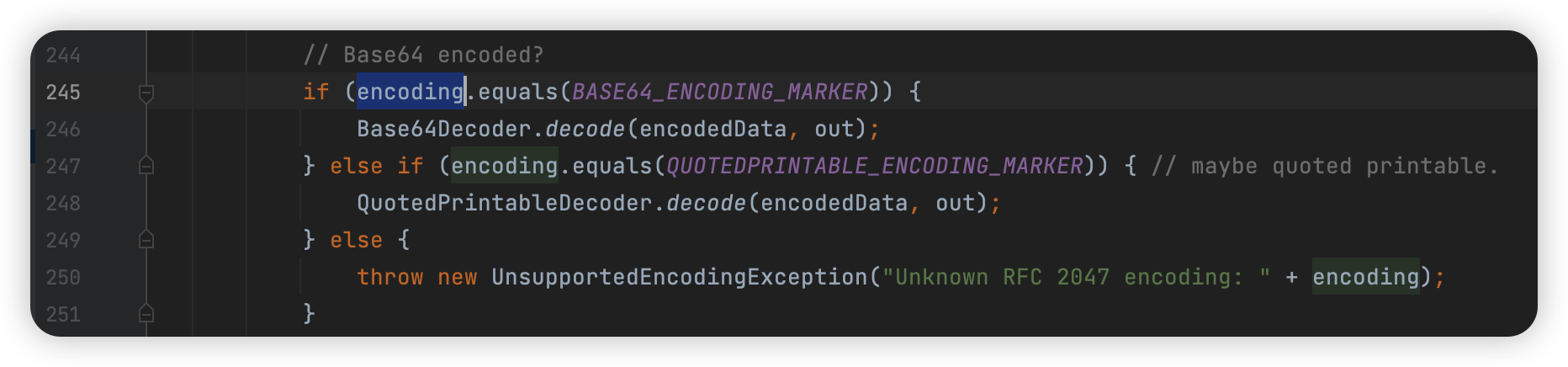
encoding 有两个选择,一个是 B,就是第一个,代表 BASE64
第二个就是 Q,代表 QuotedPrintable 编码。
然后做完解码以后还有 charset 解码的:
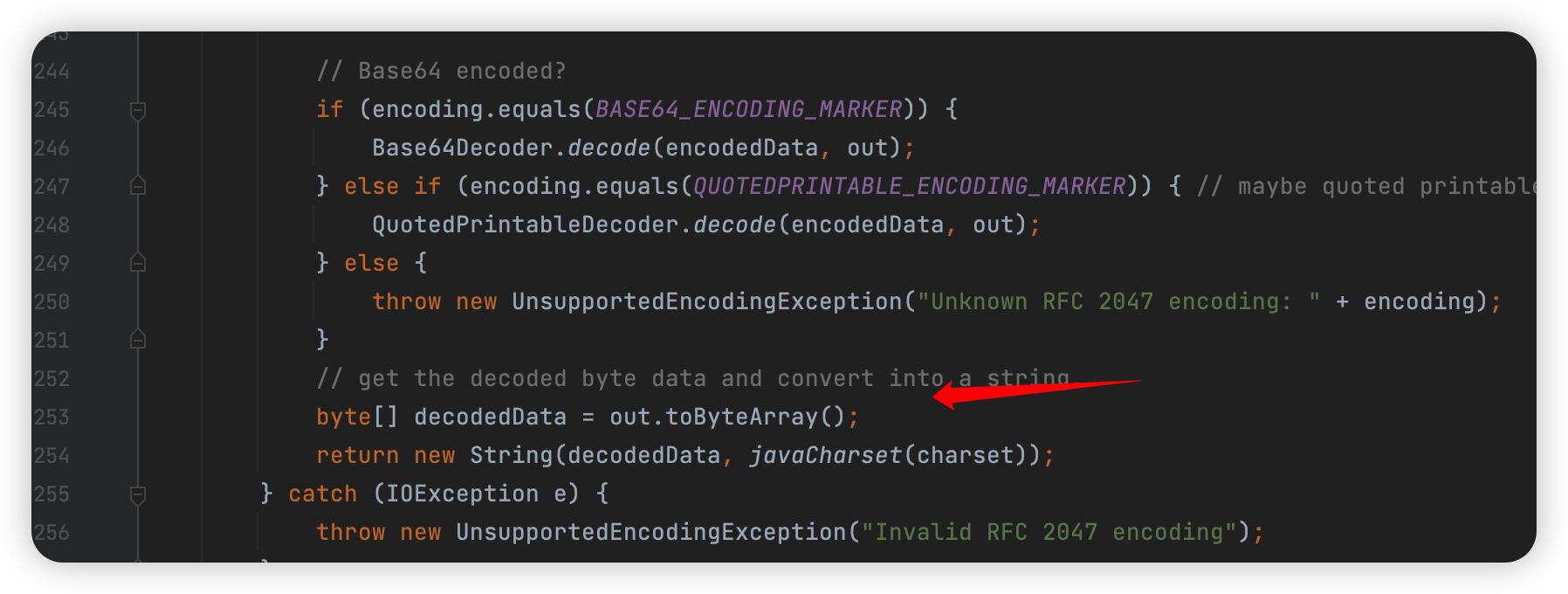
支持的编码如下:
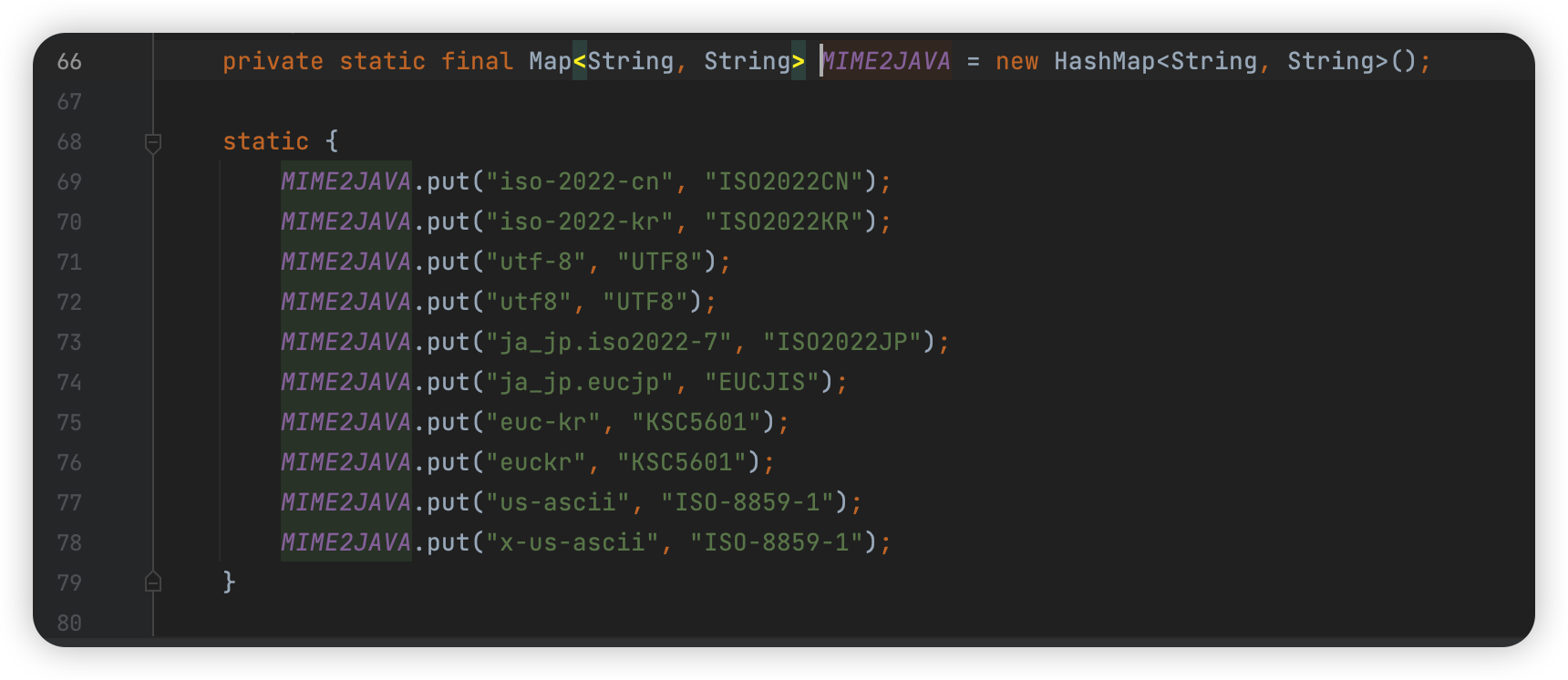
但是这个编码好像都没啥跟 utf16 一样会变化很大的,所以没啥可利用的。
最后 Content-Type 设置成这样:
1 | Content-Type: multipart/form-data,,,,,,, boundary="=?utf8?B?54mb6YC854mb6YC854mb6YC8MQ==?=",123456" |
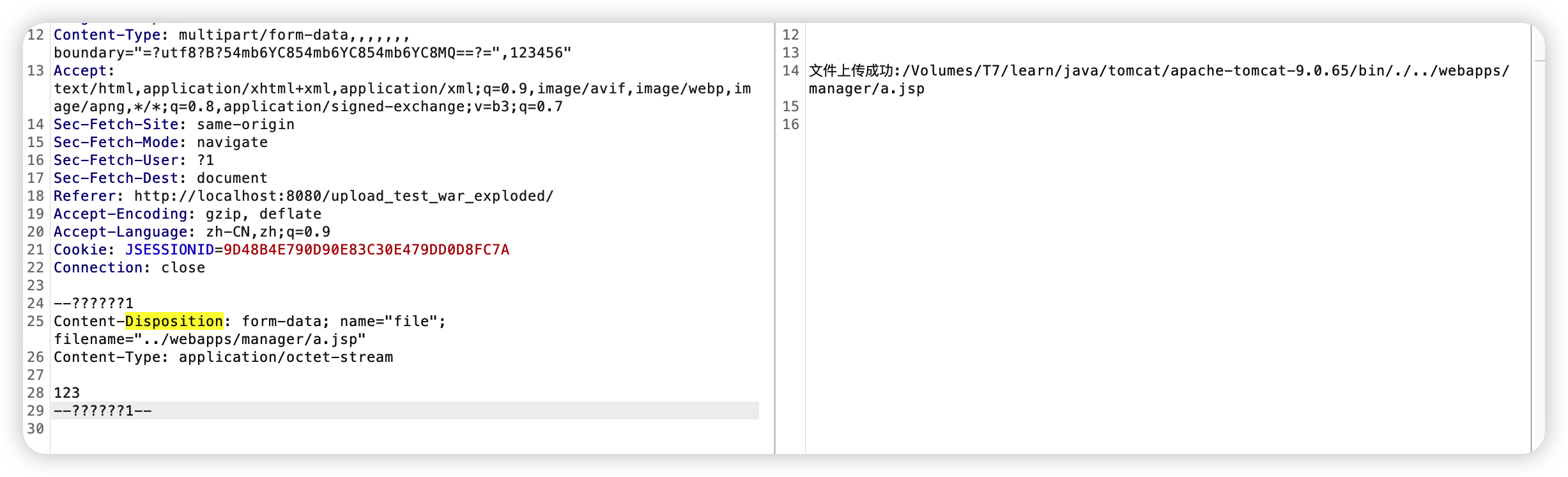
这里 Base64 用 QuotedPrintable 也可以,然后这里下面之所以是几个问号,是因为我的base64 加密的是 牛逼牛逼牛逼1 这几个字符解码之后返回到 getBoundary 函数:
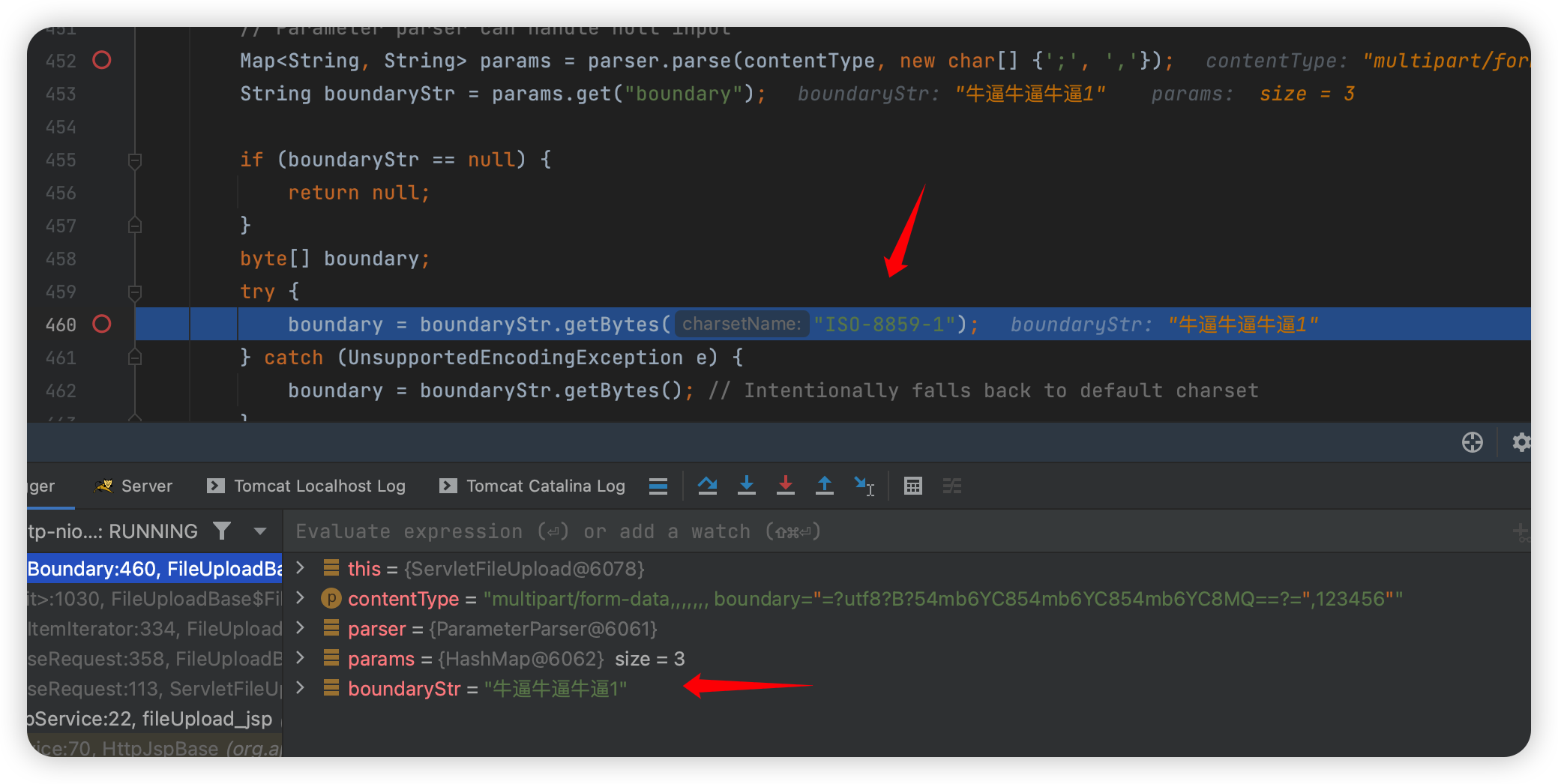
可以看到虽然 UTF8 解码成功了,但是这里会做一次 ISO-8859-1 的转码,导致直接把中文转成了 问号:

大概就是这样~
至于 Boundary 前面加个 – 是因为在获取 body 中的 bounday 的函数:
t
1 | org.apache.commons.fileupload.MultipartStream#MultipartStream(java.io.InputStream, byte[], int, org.apache.commons.fileupload.MultipartStream.ProgressNotifier) |
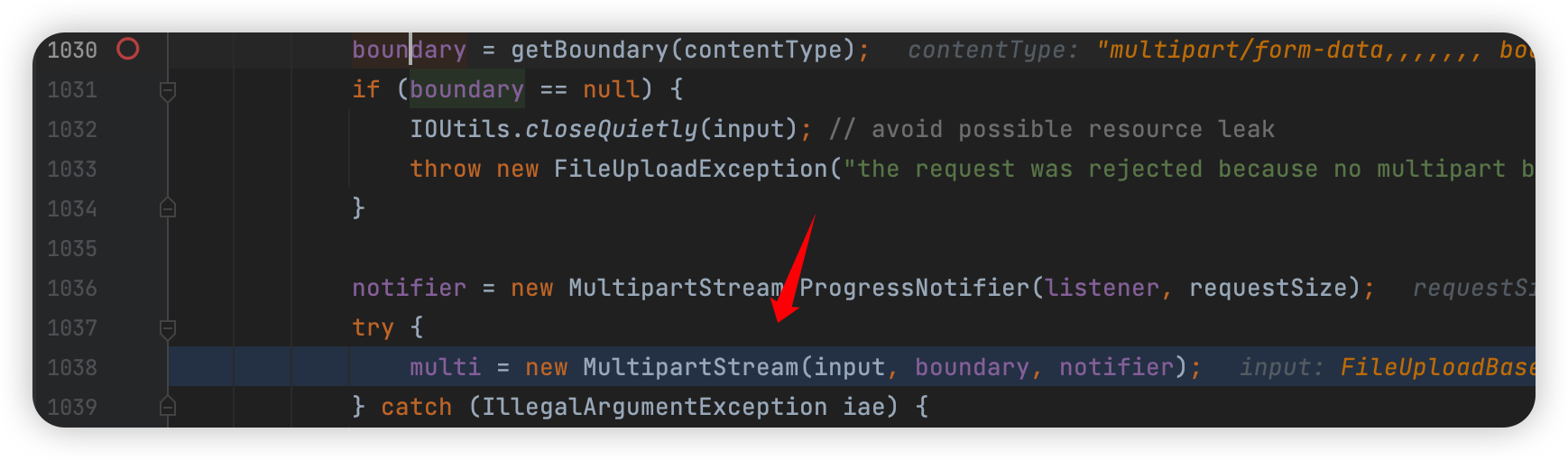

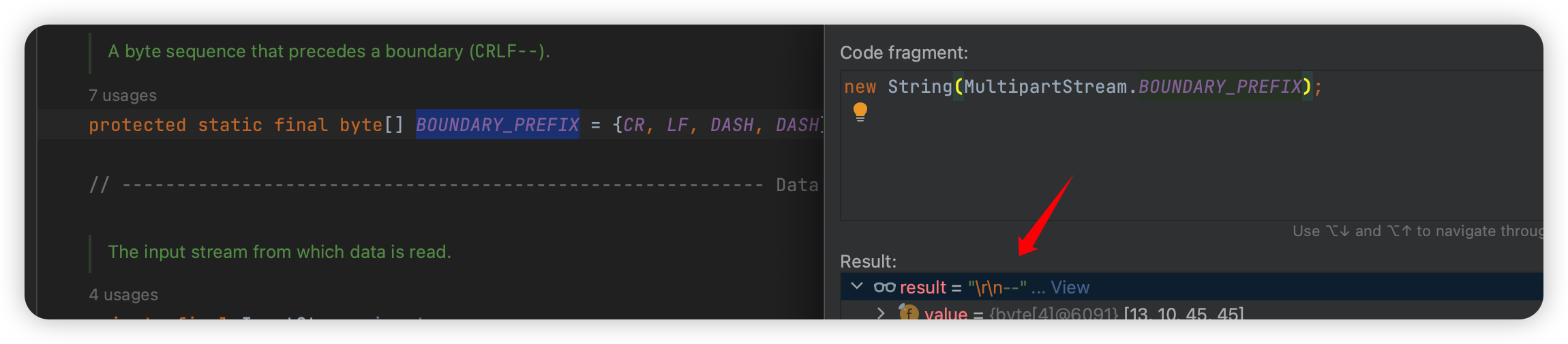
就是往前面加了个 \r\n--
然后这里还有个小细节还是在 :
org.apache.commons.fileupload.util.mime.MimeUtility#decodeText
简单解释下就是如果当前是 \t\r\n空格 这四个字符,那么就跳过,然后往下解码
然后再构造一下:
1 | Content-Type: multipart/form-data,,,,,,, boundary="=?utf8?B?MTIz?= =?utf8?Q?=34=35=36?=",123456" |

前面 base64 是123,后面 QuotePrintable 是 456。
然后 QuotePrintable 解码的时候还会把 _ 替换成 空格,所以再瞎写写:
org.apache.commons.fileupload.util.mime.QuotedPrintableDecoder#decode
快进一下,现在知道这个 parser 会做上面的一些解析,那么:
获取 name 和 filename 的地方都调用了。
然后我还发现一处:
1 | org.apache.commons.fileupload.FileUploadBase.FileItemIteratorImpl#findNextItem |
这里写了如果文件或者字段的 Content-Type 是 mixed,那么就可以再套一层:
最终写出如下
1 | POST /upload_test_war_exploded/fileUpload.jsp HTTP/1.1 |
不过这个 haihaiha的长度,必须小于这个 1234 5 6
然后到这里差不多整个 commons-upload 可能绕过的点就列出来了,当然可能还有没有的,之后有机会再看看吧~
Tomcat manager 上传 war 时的一些绕过
首先进入 manager 后,上传点在:
1 | org.apache.catalina.manager.HTMLManagerServlet#doPost -> |
然后:
看看这个函数:
1 | org.apache.catalina.core.ApplicationPart#getSubmittedFileName |
这里有个第一个点就是,是否可以让 Content-Disposition 以 attachment 开头,答案是不行的,因为在这个函数上面的 upload ,函数会有一个操作:
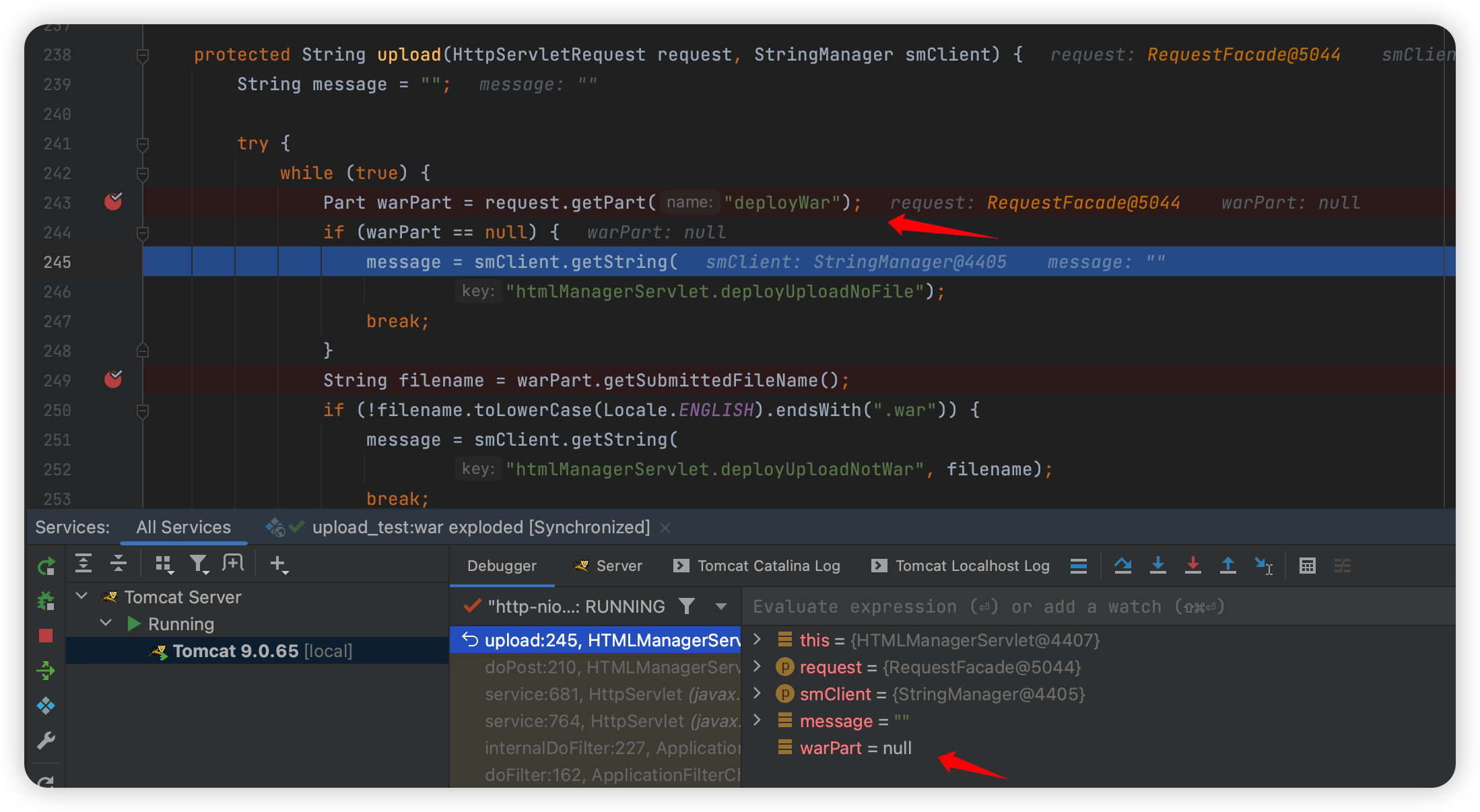
这里 getPart 是从 tomcat 里面获取的,但是在 tomcat 解析的时候有个问题:
1 | org.apache.tomcat.util.http.fileupload.FileUploadBase#getFieldName(java.lang.String) |
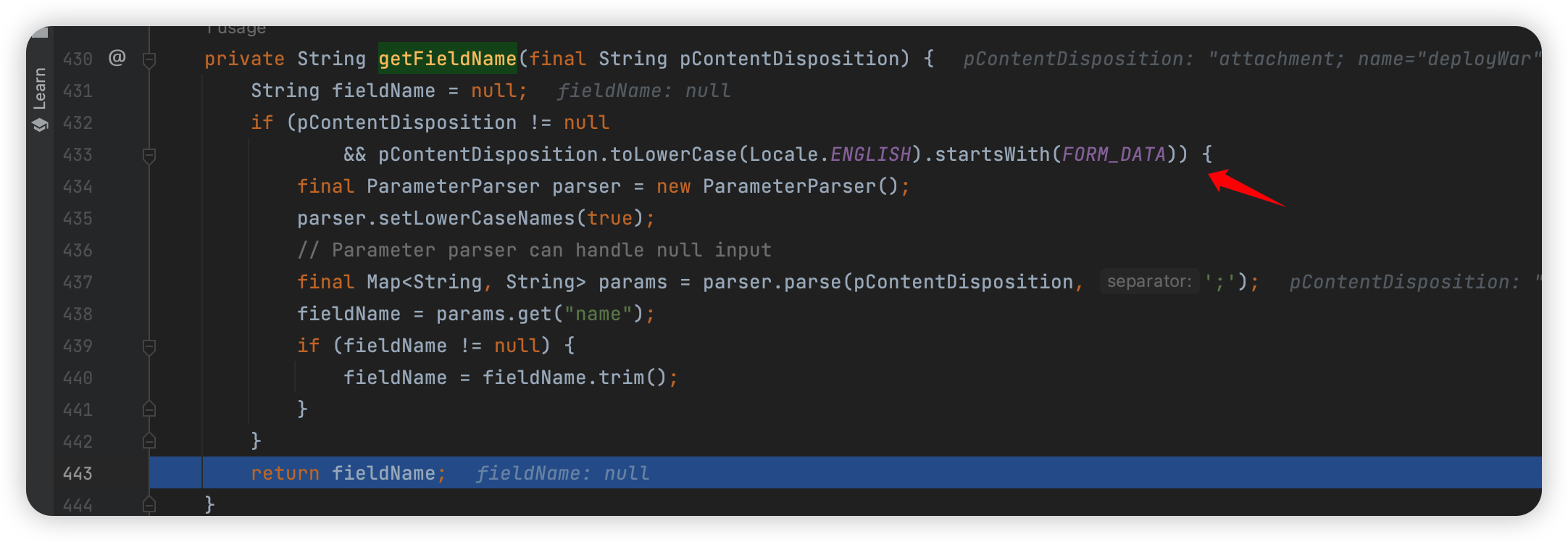
这里必须是 form-data 开头。
所以那个 attachment 就不能用了~
然后继续往 getSubmittedFileName 下面走:
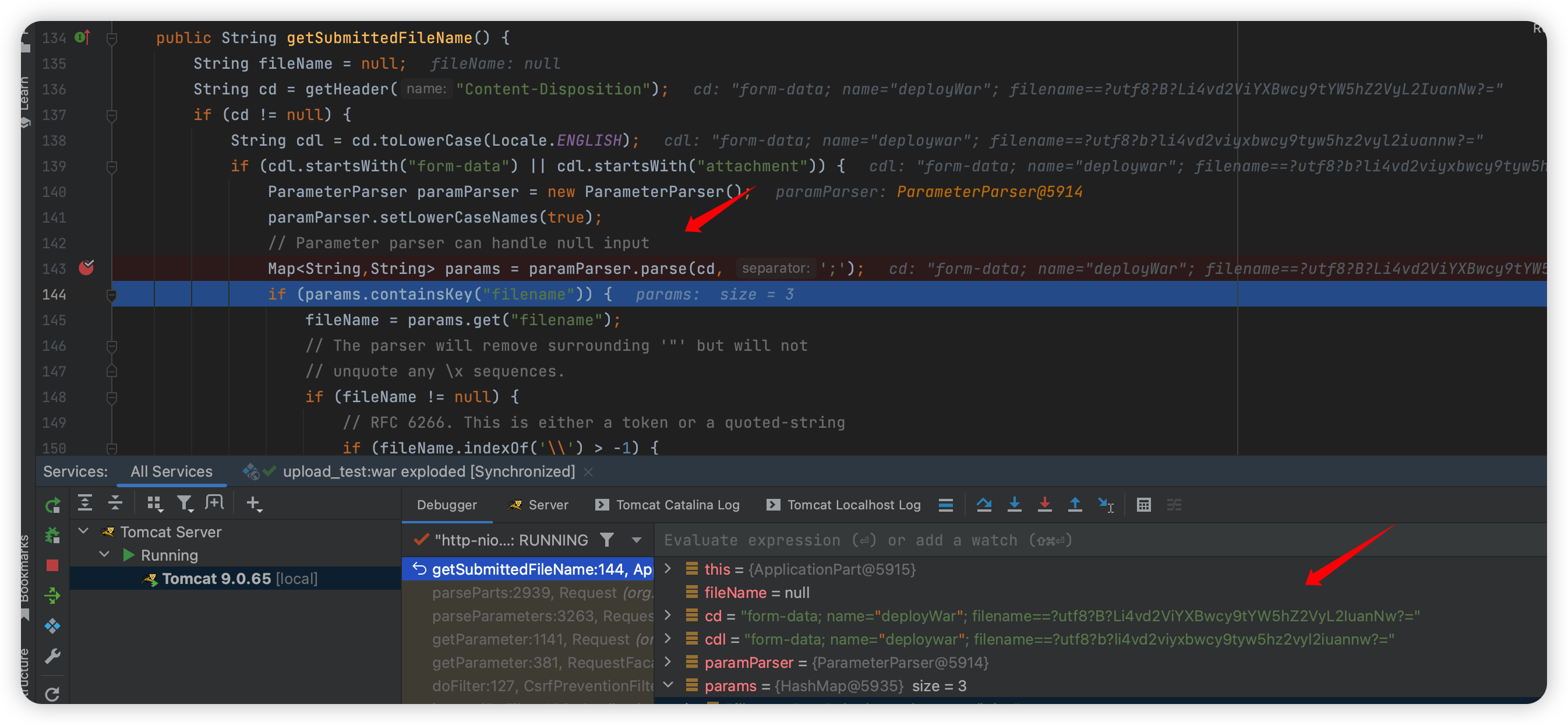
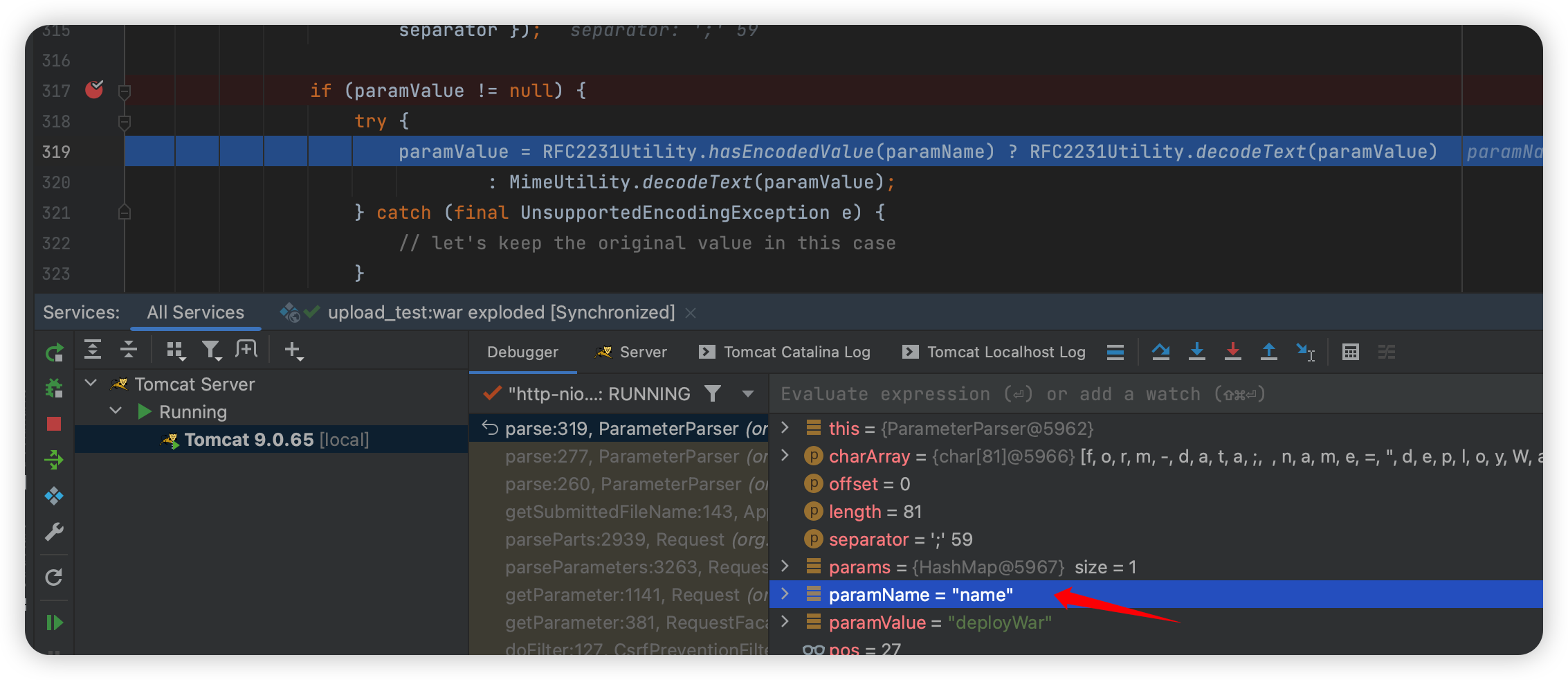
进入 parse,这里的 parse 和刚刚分析的稍有不同:
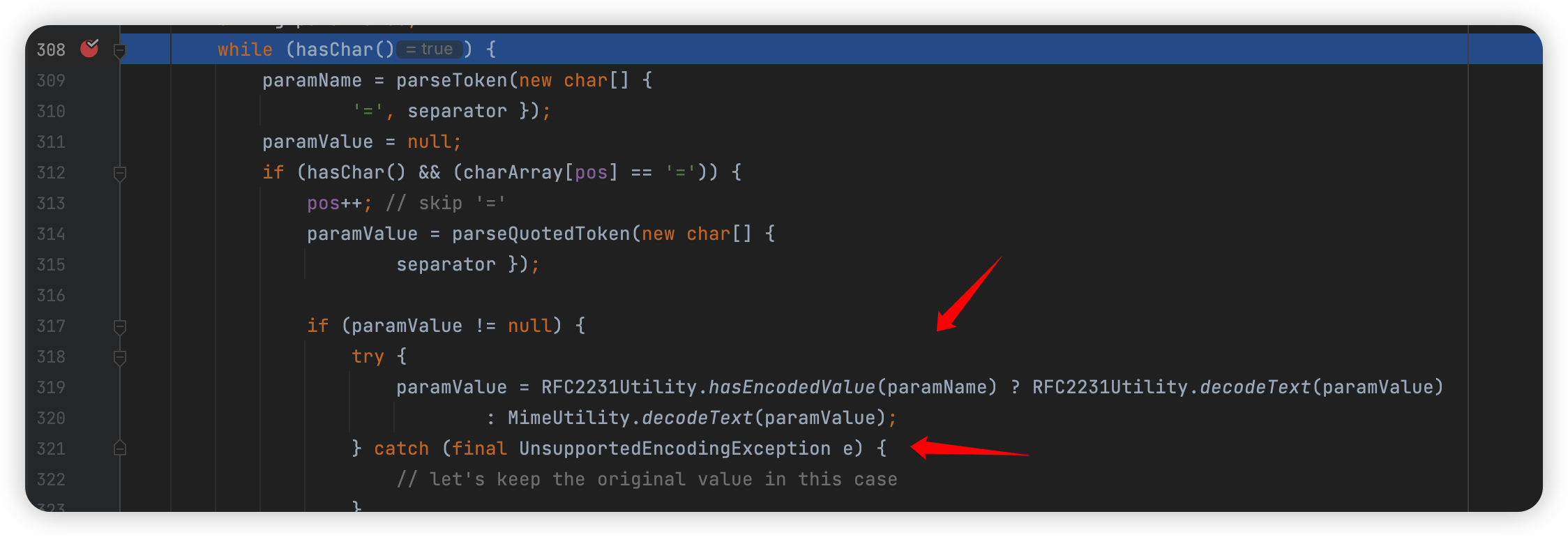
这里的 MimeUtility 就是最开始提到的,但是这个 RFC2231 是新的,我们可以看看:
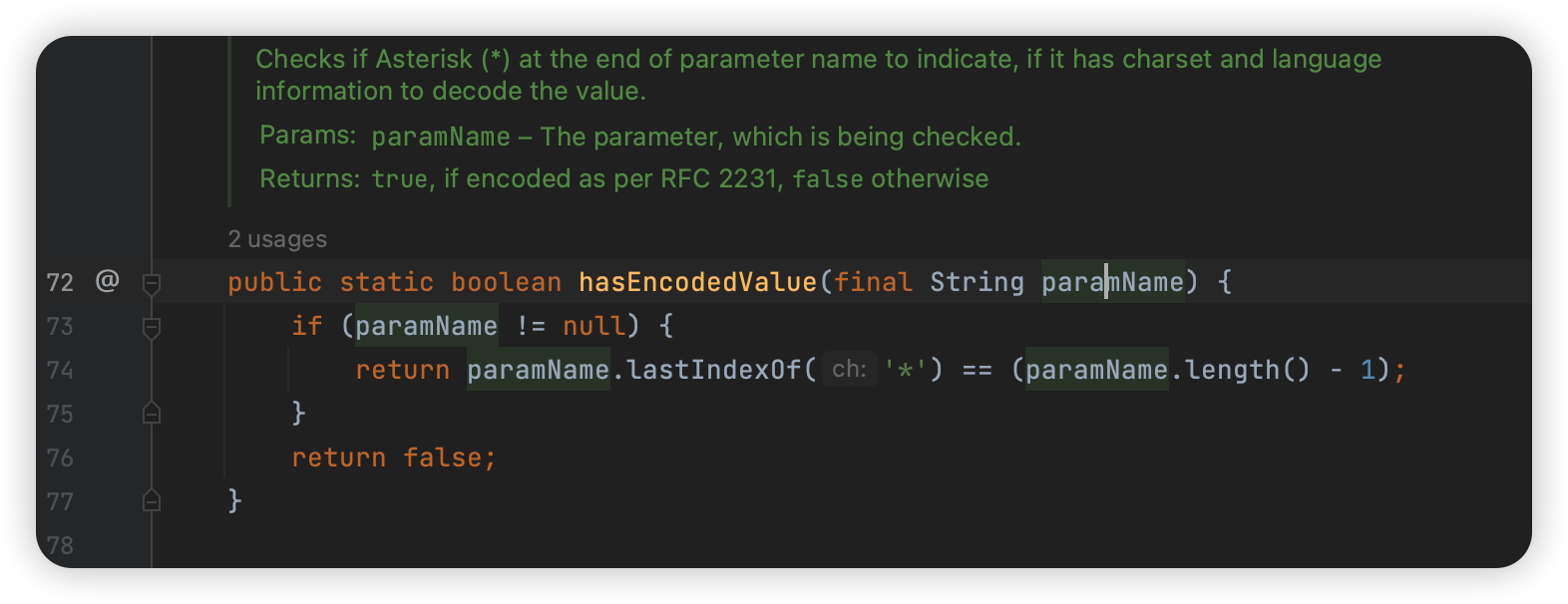
就是判断等于号前面值的最后一位是不是 *:
如果是的话就调用 RFC2231 解码 value:
1 | org.apache.tomcat.util.http.fileupload.util.mime.RFC2231Utility#decodeText |
当然,与其参考看代码,不如直接看 RFC:
https://datatracker.ietf.org/doc/html/rfc2231#section-4
1 | Content-Type: application/x-stuff; |
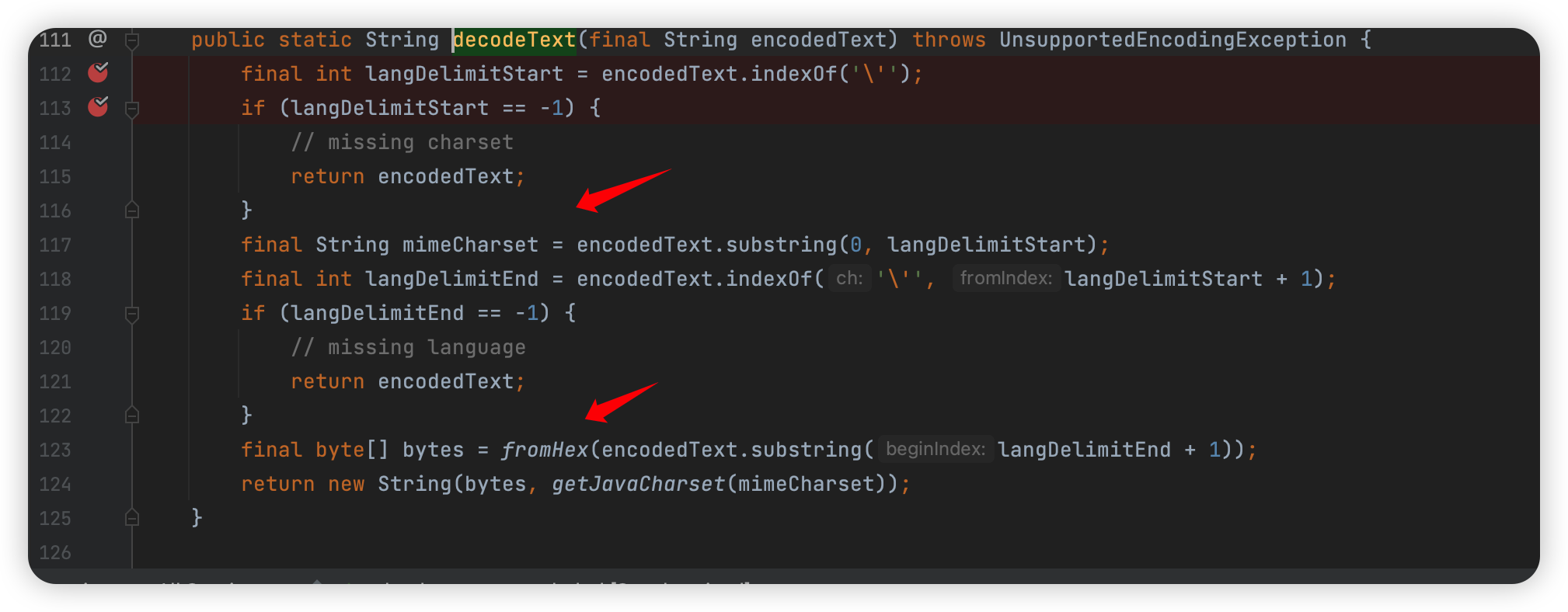
代码也很简单,就是找到第一个单引号之前作为编码,然后单引号中间的应该没啥用,然后 fromHex 就是 url 解码剩下的。
那么大概就可以这么做:
1 | Content-Disposition:form-data; name="deployWar"; filename*=utf-16'哈哈哈'%ff%fea%00b%00c%00.%00w%00a%00r%00 |
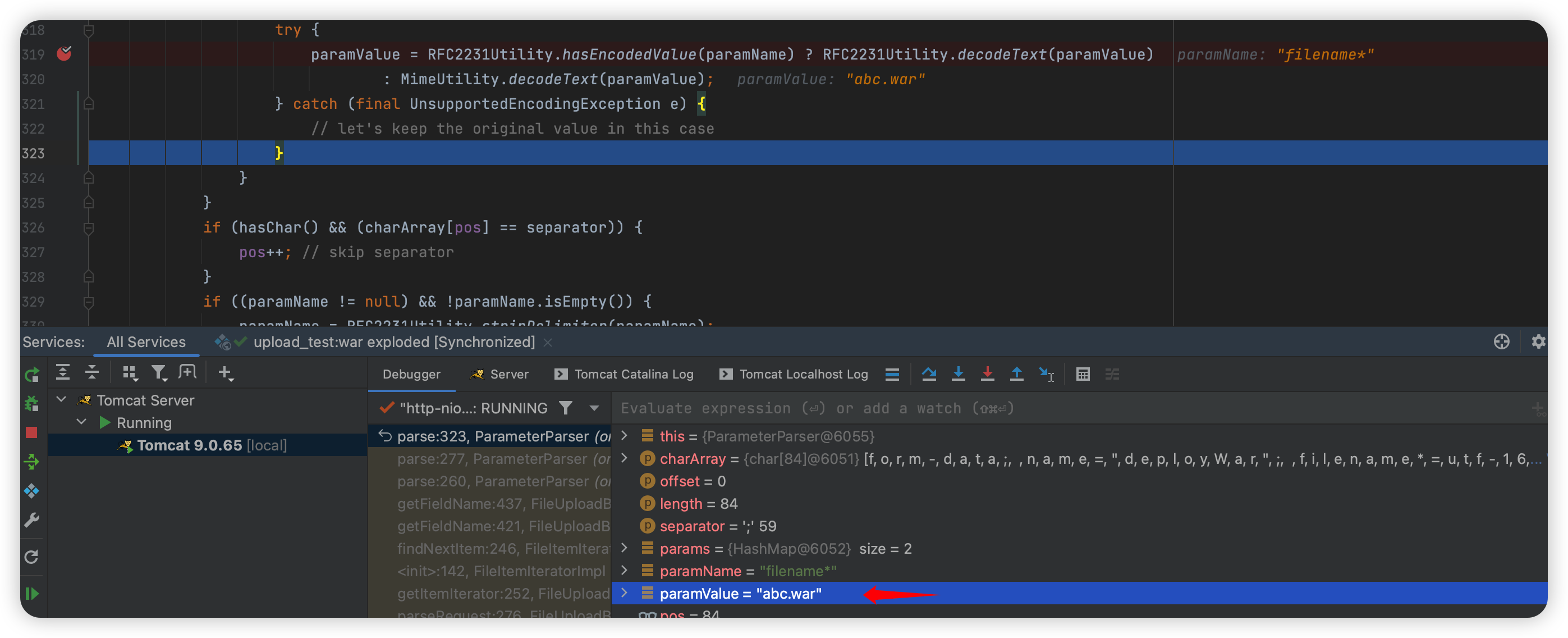
然后往下走:
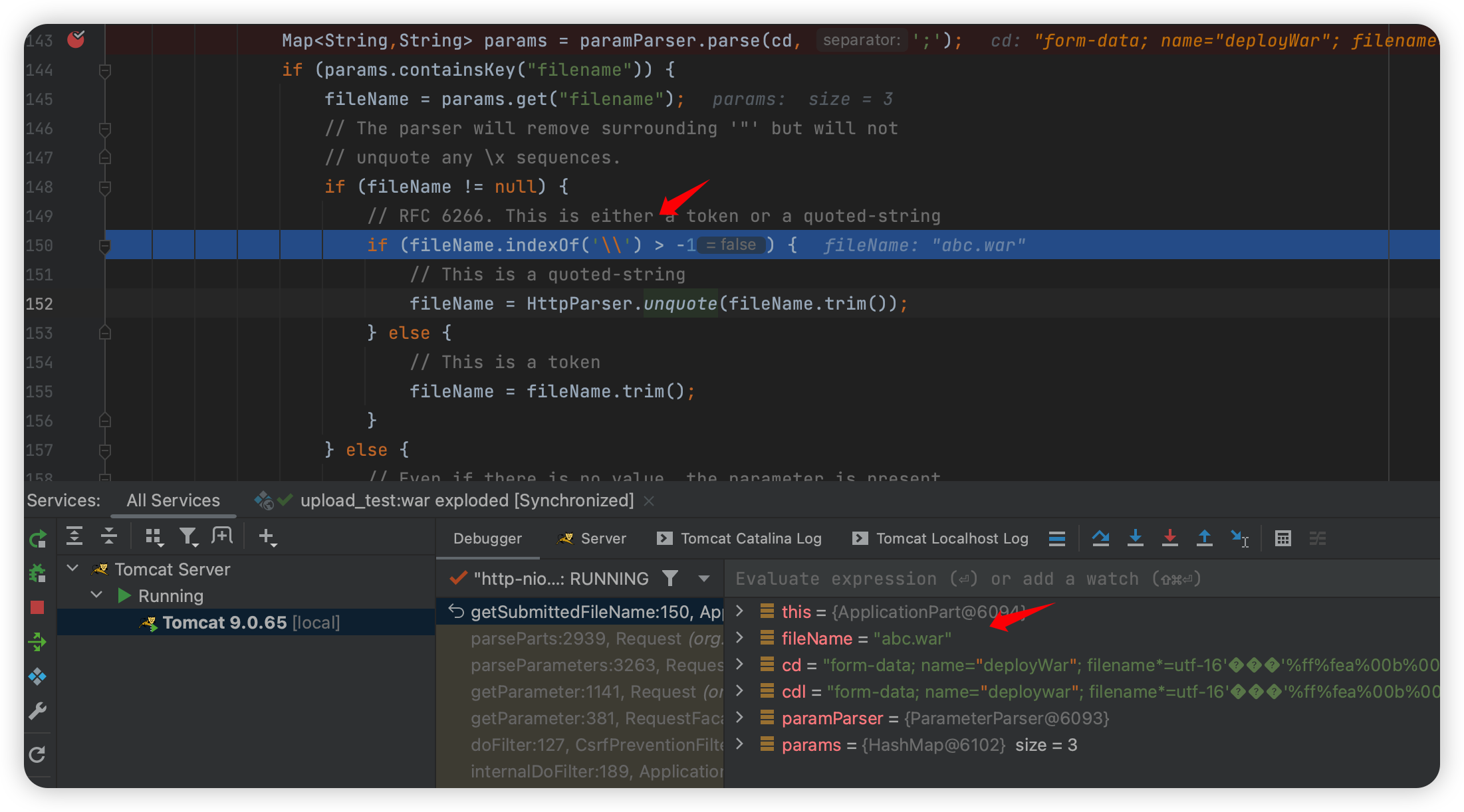
当文件名中有 \的时候,进入 unqote:
1 | org.apache.tomcat.util.http.parser.HttpParser#unquote |
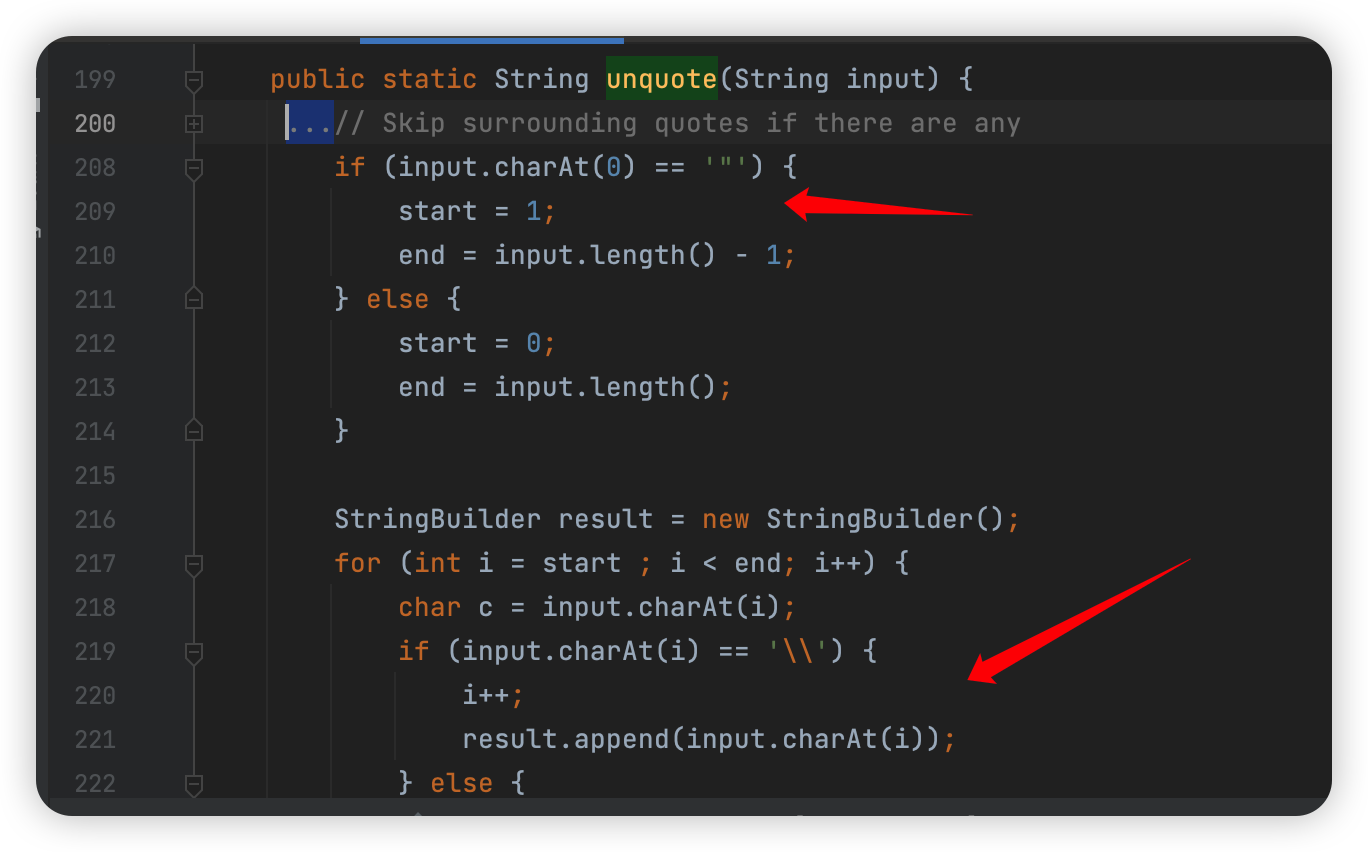
这里也简单,两块内容,一块是当文件的第一位是 ",就截取第一个,然后最后也少一个。第二块是当前字符如果是 \,那么就把下一个字符加进去。
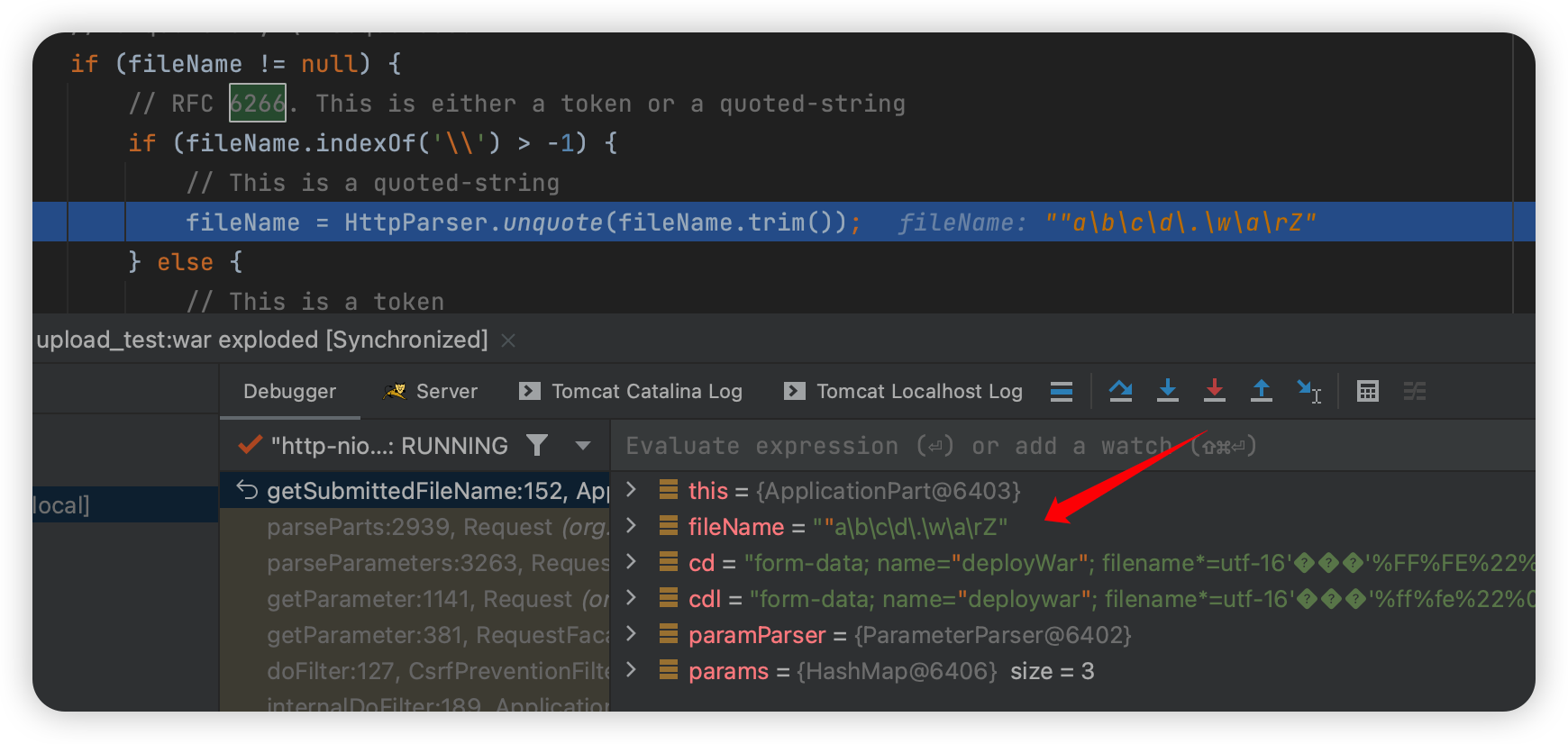
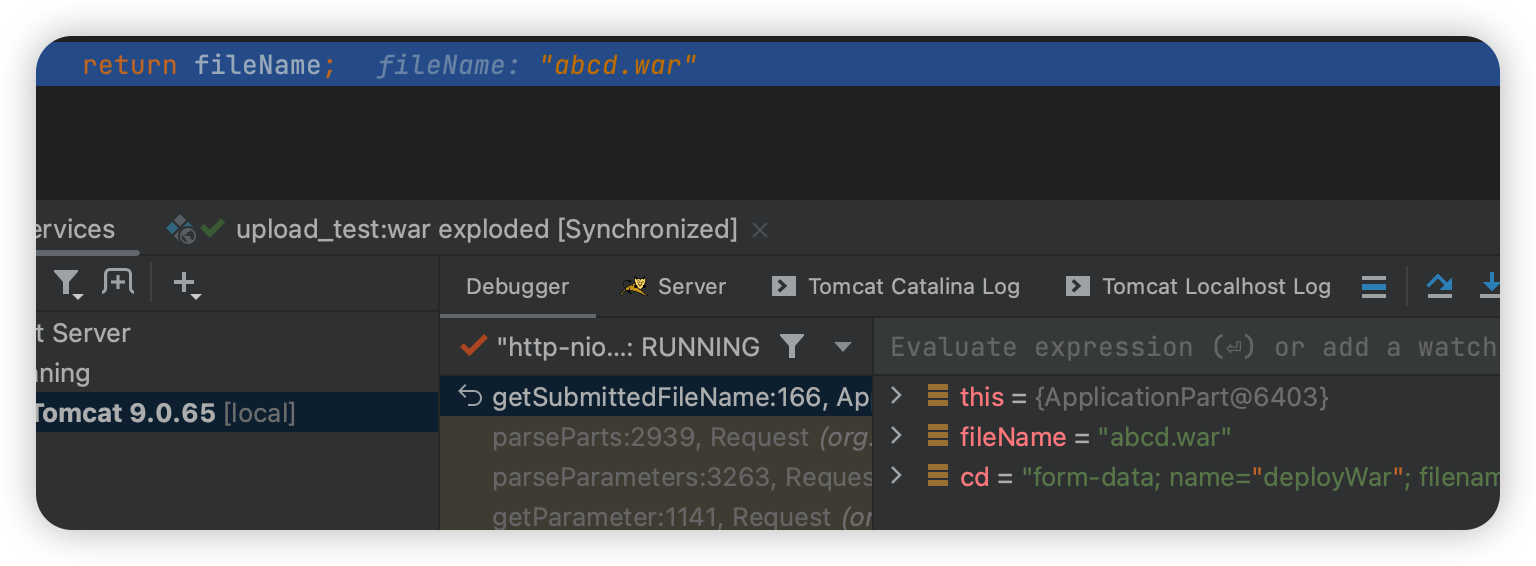
然后结合一下:

1 | Content-Disposition:form-data; name="deployWar"; filename*=utf-16'ÈÈÈ'%FF%FE%22%00a%00%5C%00b%00%5C%00c%00%5C%00d%00%5C%00.%00%5C%00w%00%5C%00a%00%5C%00r%00Z%00 |
Spring 中的文件上传
还是用 gpt 写个 spring 的文件上传:
spring-core 5
然后首先 spring 的版本是:
传一个 tomcat 那样的payload 看看:

会发现报错了:
然后就是函数:
1 | org.springframework.http.ContentDisposition#parse |
就如果是 filename* 的话,那就只能用 UTF_8 或者这个 ISO 8859 ,下面的 decodeFilename 函数就是 url 解码。
然后返回到这个函数:
1 | org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest |
这个就不用多说了,也是调用的 MimeUtility.decodeText,但是这里调用的其实是:
所以是要加个依赖的:
否则就报错了:

然后 y4 师傅在文章中提到 spring5 可以做双写,我觉得问题还是在 parse 中:
1 | org.springframework.http.ContentDisposition#parse |
后面的 filename 会覆盖前面的,感觉没啥好讨论的。
spring-core 6
依然还是这两个函数:
1 | org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest |
这里对 filename 的处理有两处:
第一处是如果是 filename* ,那么就会进入 decodeFilename,这里面应该还是 url 解码的。
然后第二处的话代码也分两段:
第一段判断如果不是 =?开头的话,就判断是否有 \在文件名里,如果有就调用 decodeQuotedPairs,之前在讨论过,就是把文件名从 a\b\c 变成abc的
然后第二段:
值得一提的是 spring6 自己实现了 QP 的编码了:
1 | org.springframework.http.ContentDisposition#decodeQuotedPrintableFilename |
这样就可以使用 qp 编码啦~
当然不只是 qp 编码,上面的代码还有个叫 charset 的变量,他是从正则中匹配出来的:
1 | Pattern BASE64_ENCODED_PATTERN = Pattern.compile("=\\?([0-9a-zA-Z-_]+)\\?B\\?([+/0-9a-zA-Z]+=*)\\?="); |
反正也很简单,就是前面加个编码,类似如下:

1 | Content-Disposition:form-data; name="file"; filename==?utf-16?B?//5oAGEAaQAxADIAMwAuAHQAeAB0AA==?= |
然后,大概就这么多吧~~~